Go Scheduler
Contents
- Introduction
- Compilation and Go Runtime
- Primitive Scheduler
- Scheduler Enhancement
- GMP Model
- Program Bootstrap
- Creating a Goroutine
- Schedule Loop
- Finding a Runnable Goroutine
- Goroutine Preemption
- Handling System Calls
- Network I/O and File I/O
- How netpoll Works
- Garbage Collector
- Common Functions
- Go Runtime APIs
Disclaimer
This blog post primarily focuses on Go 1.24 programming language running on Linux on ARM architecture. It may not cover platform-specific details for other operating systems or hardware architectures.
The content is based on other sources and my own understanding of Go, so it might not be entirely accurate. Feel free to correct me or give suggestions in the comment section at the very bottom 😄.
Introduction
⚠️ This post assumes that you already have a basic understanding of Go concurrency (goroutines, channels, etc.). If you’re new to these concepts, consider reviewing them before continuing.
Go or Golang, introduced in 2009, has steadily grown in popularity as a programming language for building concurrent applications. It is designed to be simple, efficient, and easy to use.
Go’s concurrency model is built around the concept of goroutines, which are lightweight user threads managed by the Go runtime on user space. Go offers useful primitives for synchronization, such as channels, to help developers write concurrent code easily. It also uses non-trivial techniques to make I/O bound programs efficient.
Understanding the Go scheduler is crucial for Go programmer to write efficient concurrent programs. It also helps us become better at troubleshooting performance issues or tuning the performance of our Go programs. In this post, we will explore how Go scheduler evolved over time, and how the Go code we write happens under the hood.
Compilation and Go Runtime
This post covers a lot of source code walkthrough, so it is better to have a basic understanding of how Go code is compiled and executed first. When a Go program is built, there are three stages:
- Compilation: Go source files (
*.go) are compiled into assembly files (*.s). - Assembling: The assembly files (
*.s) are then assembled into object files (*.o). - Linking: The object files (
*.o) are linked together to produce a single executable binary file.
flowchart LR
start((Start)) ==> |*.go files|compiler[Compiler]
compiler ==> |*.s files|assembler[Assembler]
assembler ==> |*.o files|linker[Linker]
linker ==> |Executable binary file|_end(((End)))
|
| How Go code is transformed into an executable binary file |
To understand Go scheduler, you have to understand Go runtime first. Go runtime is the core of the programming language, providing essential functionalities such as scheduling, memory managements, and data structures. It’s nothing but a collection of functions and data structures that makes Go programs work. The implementation of Go runtime can be found in runtime package. Go runtime is written in a combination of Go and assembly code, with the assembly code primarily used for low-level operations such as dealing with registers.
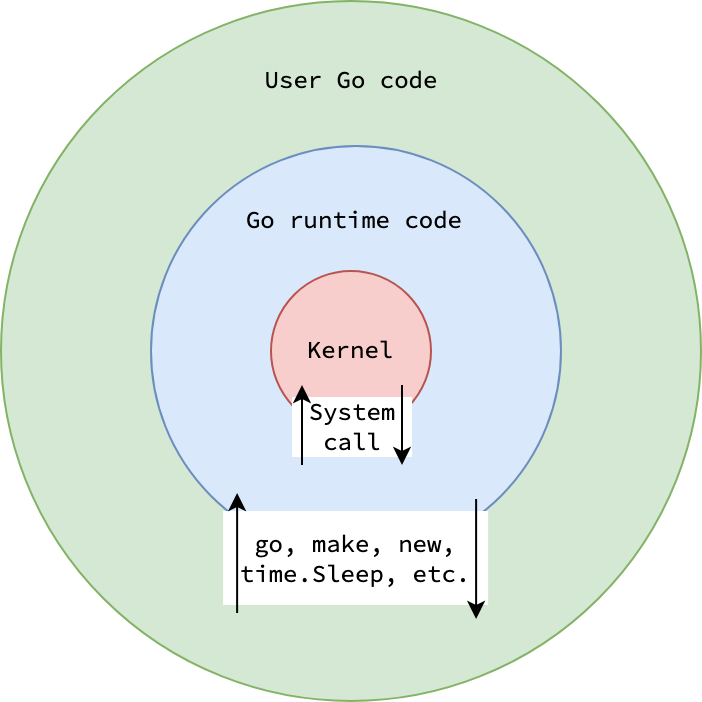 |
|---|
| The role of Go runtime |
Upon compiling, Go compiler replaces some keywords and built-in functions with Go runtime’s function calls.
For example, the go keyword—used to spawn a new goroutine—is substituted with a call to runtime.newproc, or the new function—used to allocate a new object—is replaced with a call to runtime.newobject.
You might be surprised to learn that some functions in the Go runtime have no Go implementation at all.
For example, functions like getg are recognized by the Go compiler and replaced with low-level assembly code during compilation.
Other function, such as gogo, are platform-specific and implemented entirely in assembly.
It is the responsibility of the Go linker to connect these assembly implementations with their Go declarations.
In some cases, a function appears to have no implementation in its package, but is actually linked to a definition in the Go runtime using the //go:linkname compiler directive.
For instance, the commonly used time.Sleep function is linked to its actual implementation at runtime.timeSleep
Primitive Scheduler
⚠️ The Go scheduler isn’t a standalone object, but rather a collection of functions that facilitate the scheduling. Additionally, it doesn’t run on a dedicated thread; instead, it runs on the same threads that goroutines run on. These concepts will become clearer as you read through the rest of the post.
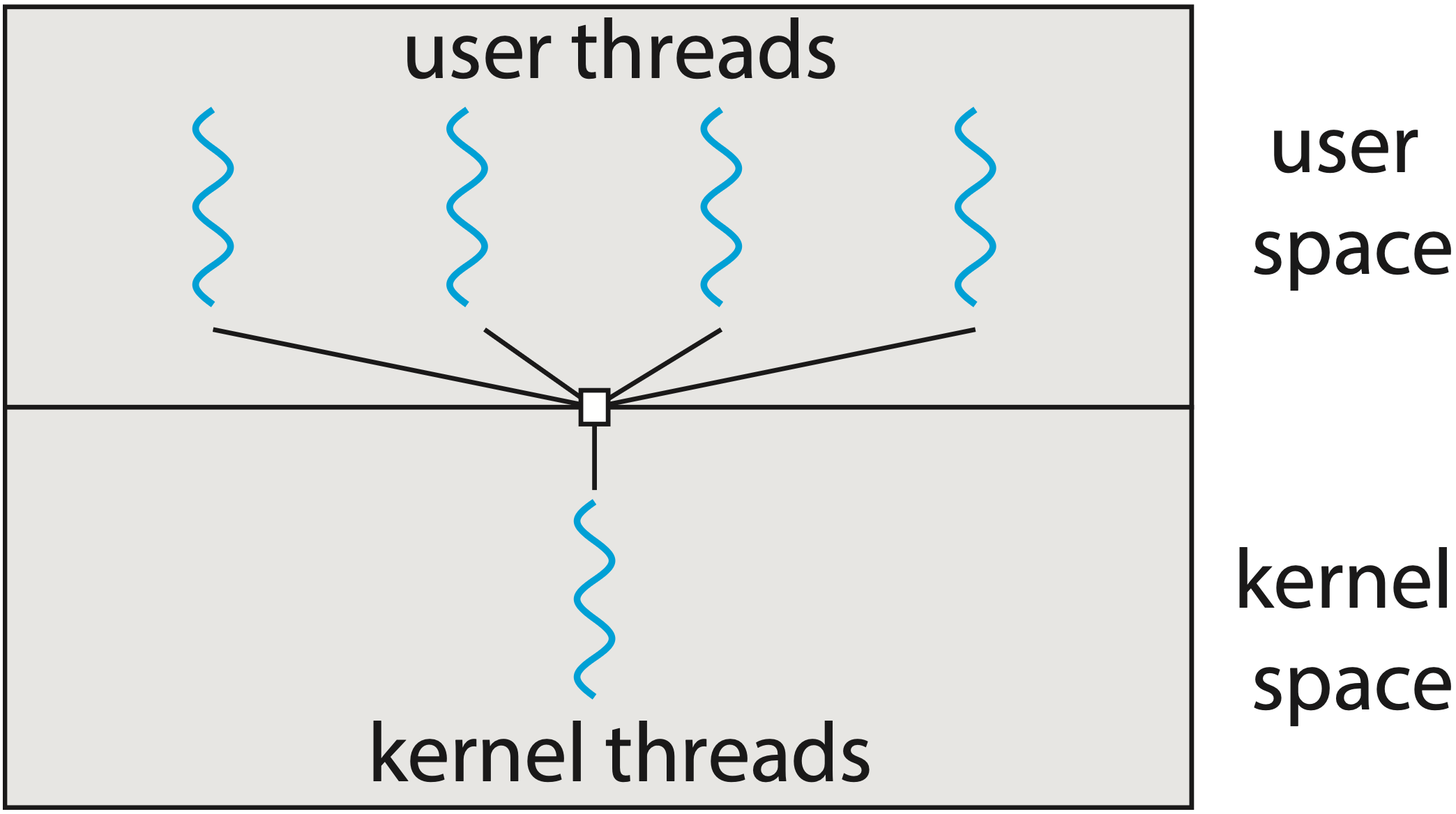
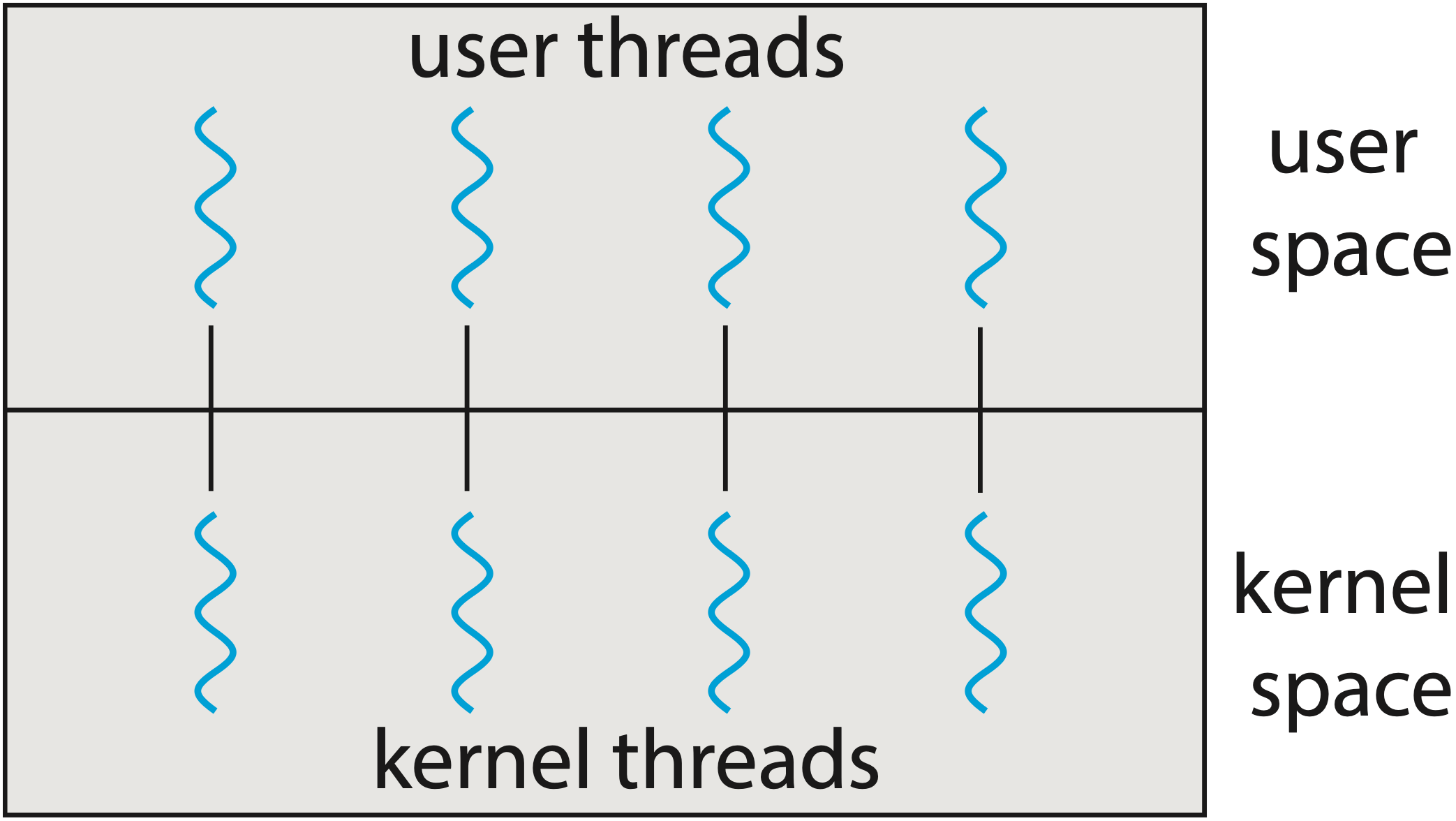
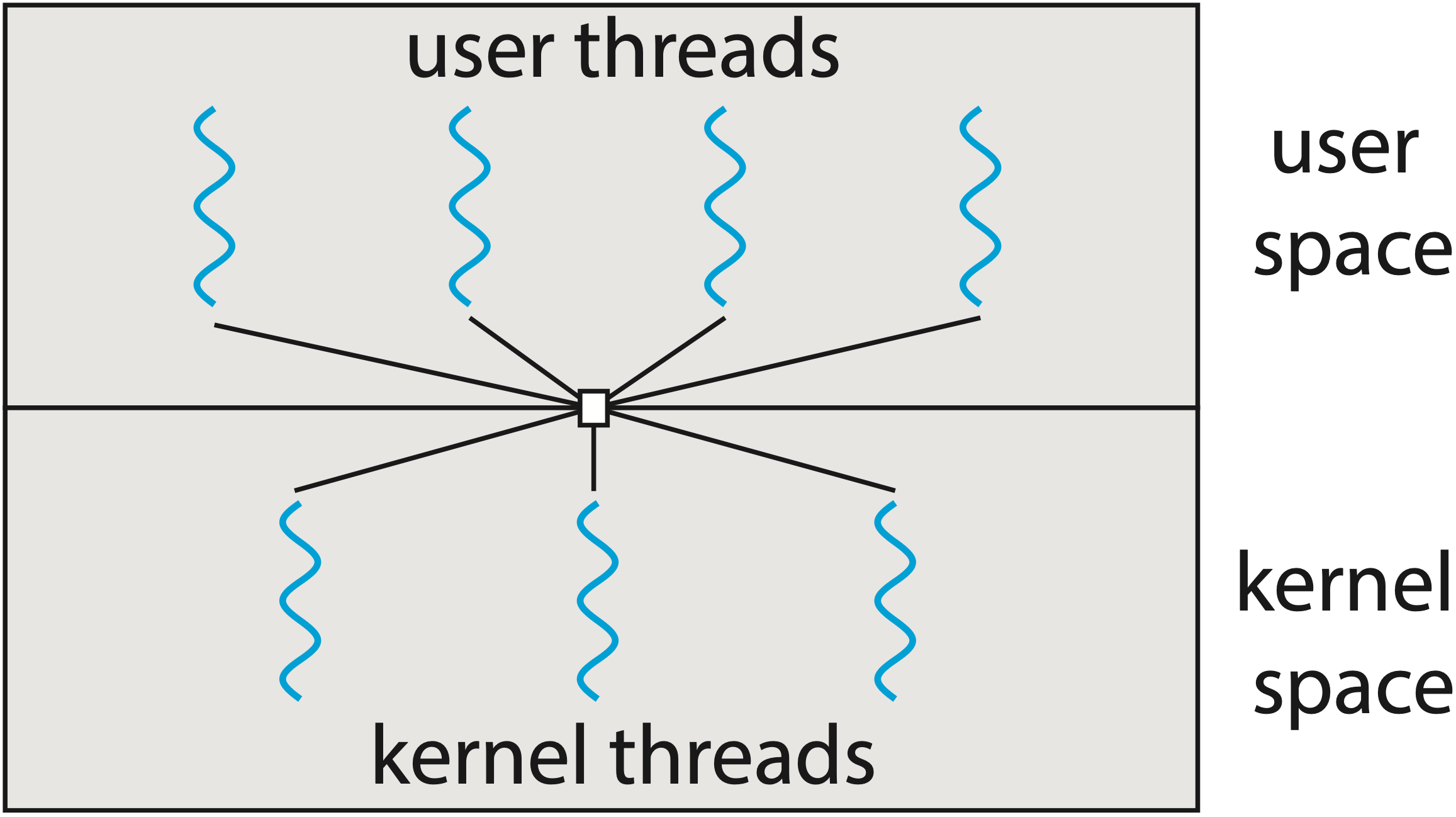
If you’ve ever worked in concurrency programming, you might be familiar with multithreading models. It specifies how user-space threads (coroutines in Kotlin, Lua or goroutines in Go) are multiplexed onto single or multiple kernel threads. Typically, there are three models: many-to-one (N:1), one-to-one (1:1), and many-to-many (M:N).
 |
 |
 |
|---|---|---|
| Many-to-one multithreading model1 |
One-to-one multithreading model2 |
Many-to-many multithreading model3 |
Go opts for the many-to-many (M:N) threading model, which allows multiple goroutines to be multiplexed onto multiple kernel threads. This approach sacrifices complexity to take advantage of multicore system and make Go program efficient with system calls, addressing the problems of both N:1 and 1:1 models. As kernel doesn’t know what goroutine is and only offers thread as concurrency unit to user-space application, it is the kernel thread that runs scheduling logic, executes goroutine code, and makes system call on behalf of goroutines.
In the early days, particularly before version 1.1, Go implemented the M:N multithreading model in a naive way.
There were only two entities: goroutines (G) and kernel threads (M, or machines).
A single global run queue was used to store all runnable goroutines and guarded with lock to prevent race condition.
The scheduler—running on every thread M—was responsible for selecting a goroutine from the global run queue and executing it.
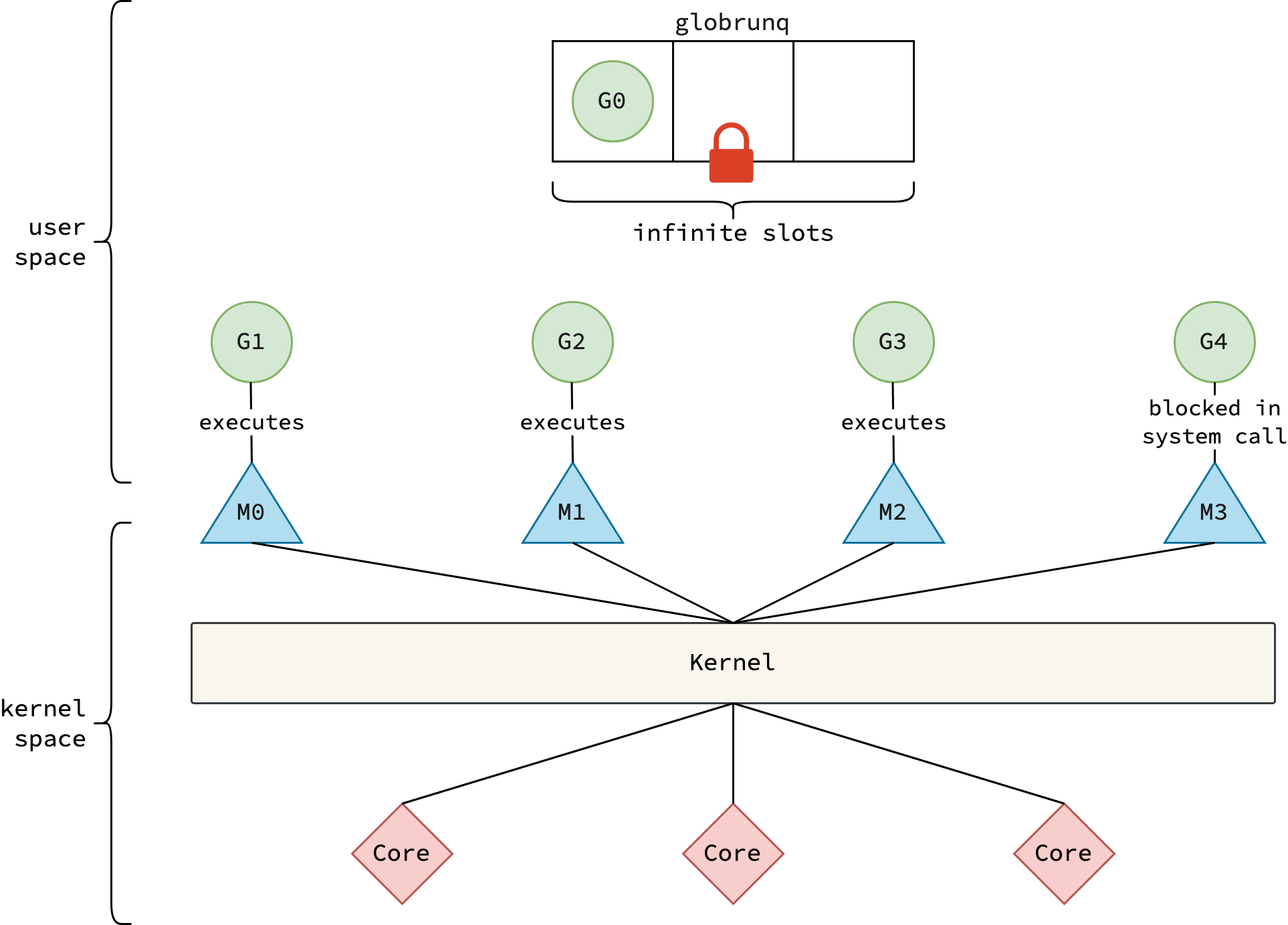 |
|---|
| Go’s primitive scheduler |
Nowadays, Go is well-known for its performant concurrency model. Unfortunately, that’s not the case for the early Go. Dmitry Vyukov—one of the key Go contributors—pointed out multiple issues with this implementation in his famous Scalable Go Scheduler Design: “In general, the scheduler may inhibit users from using idiomatic fine-grained concurrency where performance is critical.” Let me explain in more detail what he meant.
Firstly, the global run queue was a bottleneck for performance. When a goroutine was created, threads had to acquire a lock to put it into the global run queue. Similarly, when threads wanted to pick up a goroutine from the global run queue, they also had to acquire the lock. You may know that locking is not free, it does have overhead with lock contention. Lock contention leads to performance degradation, especially in high-concurrency scenarios.
Secondly, threads frequently handoff its associated goroutine to another thread. This cause poor locality and excessive context switch overhead. Child goroutine usually wants to communicate with its parent goroutine. Therefore, making child goroutine run on the same thread as its parent goroutine is more performant.
Thirdly, as Go’s been using Thread-caching Malloc, every thread M has a thread-local cache mcache so that it can use for allocation or to hold free memory.
While mcache is only used by Ms executing Go code, it is even attached with Ms blocking in a system call, which don’t use mcache at all.
An mcache can take up to 2MB of memory, and it is not freed until thread M is destroyed.
Because the ratio between Ms running Go code and all Ms can be as high as 1:100 (too many threads are blocking in system call), this could lead to excessive resource consumption and poor data locality.
Scheduler Enhancement
Now that you have a understanding of the issues with early Go scheduler, let’s examine some of the enhancement proposals to see how Go team addressed these issues so that we have a performant scheduler today.
Proposal 1: Introduction of Local Run Queue
Each thread M is equipped with a local run queue to store runnable goroutines.
When a running goroutine G on thread M spawns a new goroutine G1 using the go keyword, G1 is added to M’s local run queue.
If the local queue is full, G1 is instead placed in the global run queue.
When selecting a goroutine to execute, M first checks its local run queue before consulting the global run queue.
Thus, this proposal addresses the first and second issues as described in the last section.
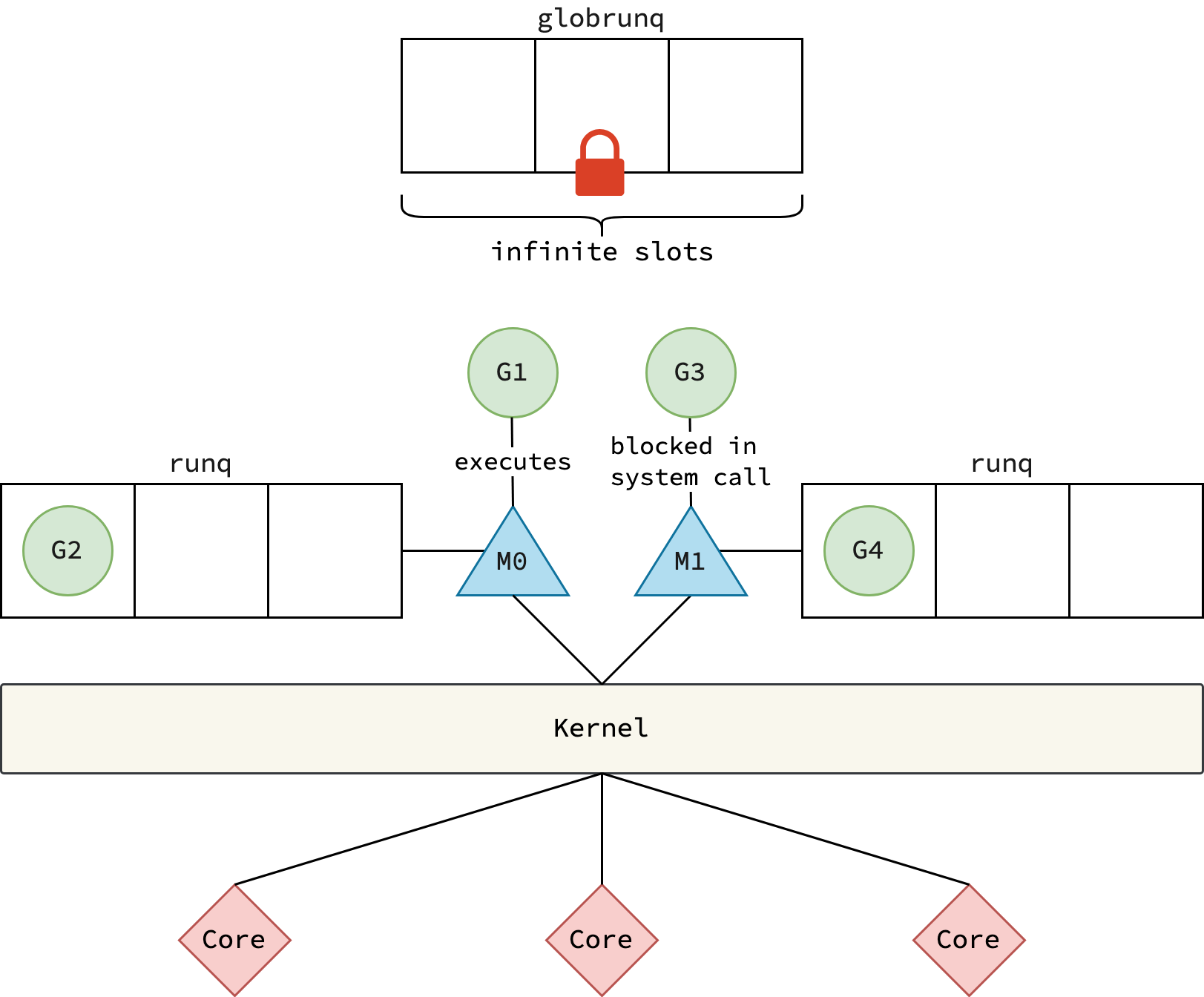 |
|---|
| Proposal 1 for scheduler enhancement |
However, it can’t resolve the third issue.
When many threads M are blocked in system calls, their mcache stays attached, causing high memory usage by the Go scheduler itself, not to mention the memory usage of the program that we—Go programmers—write.
It also introduces another performance problem.
In order to avoid starving goroutines in a blocked M’s local run queue like M1 in the figure above, the scheduler should allow other threads to steal goroutine from it.
However, with a large number of blocked threads, scanning all of them to find a non-empty run queue becomes expensive.
Proposal 2: Introduction of Logical Processor
This proposal is described in Scalable Go Scheduler Design, where the notion of logical processor P is introduced.
By logical, it means that P pretends to execute goroutine code, but in practice, it is thread M associated with P that actually performs the execution.
Thread’s local run queue and mcache are now owned by P.
This proposal effectively addresses open issues in the last section.
As mcache is now attached to P instead of M and M is detached from P when G makes system call, the memory consumption stays low when there are a large number of Ms entering system calls.
Also, as the number of P is limited, the stealing mechanism is efficient.
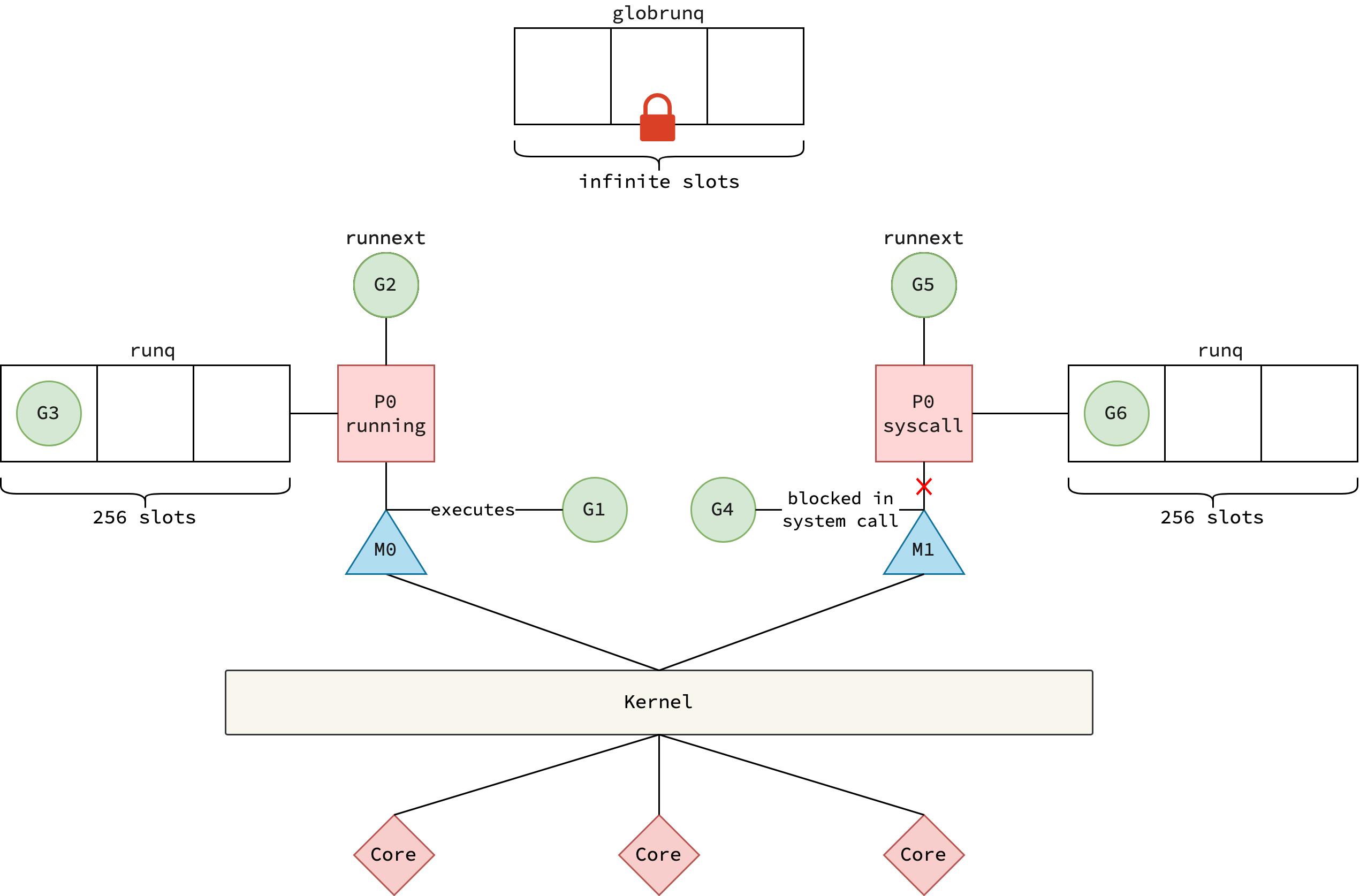 |
|---|
| Proposal 2 for scheduler enhancement |
With the introduction of logical processors, the multithreading model remains M:N. But in Go, it is specifically referred to as the GMP model as there are three kinds of entities: goroutine, thread and processor.
GMP Model
Goroutine: g
When the go keyword is followed by a function call, a new instance of g, referred to as G, is created.
G is an object that represents a goroutine, containing metadata such as its execution state, stack, and a program counter pointing to the associated function.
Executing a goroutine simply means running the function that G references.
When a goroutine finishes execution, it isn’t destroyed; instead, it becomes dead and is placed into the free list of the current processor P .
If P’s free list is full, the dead goroutine is moved to the global free list.
When a new goroutine is created, the scheduler first attempts to reuse one from the free list before allocating a new one from scratch.
This recycling mechanism makes goroutine creation significantly cheaper than creating a new thread.
The figure and table below described the state machine of goroutines in the GMP model. Some states and transitions are omitted for simplicity. The actions that trigger state transitions will be described along the post.
| State | Description |
|---|---|
| Idle | Has just been created, and not yet initialized |
| Runnable | Currently in run queue, and about to execute code |
| Running | Not in a run queue, and executing code |
| Syscall | Executing system call, and not executing code |
| Waiting | Not executing code, and not in a run queue, e.g. waiting for channel |
| Dead | Currently in a free list, just exited, or just beiging initialized |
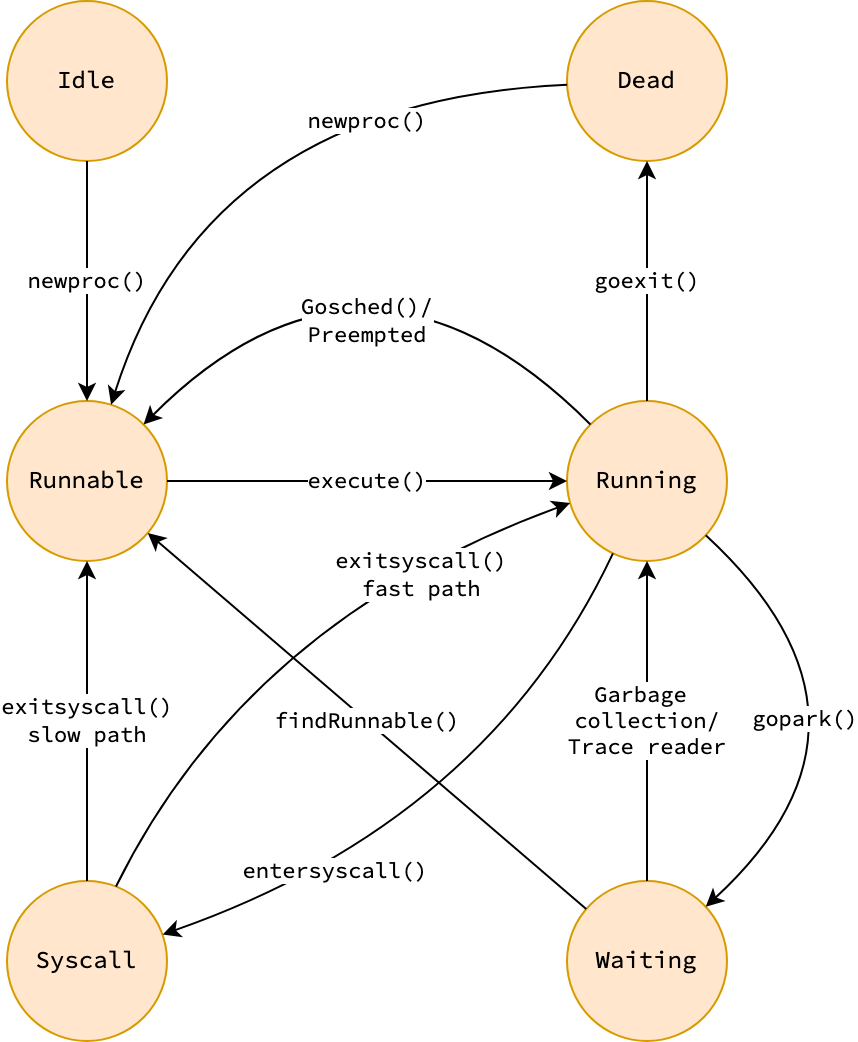 |
|---|
| State machine of goroutines in GMP model |
Thread: m
All Go code—whether it’s user code, the scheduler, or the garbage collector—runs on threads that are managed by the operating system kernel.
In order for the Go scheduler to make threads work well in GMP model, m struct representing threads is introduced, and an instance of m is called M.
M maintains reference to the current goroutine G, the current processor P if M is executing Go code, the previous processor P if M is executing system call, and the next processor P if M is about to be created.
Each M also holds reference to a special goroutine called g0, which runs on the system stack—the stack provided by the kernel to the thread.
Unlike the system stack, a regular goroutine’s stack is dynamically sized; it grows and shrinks as needed.
However, the operations for growing or shrinking a stack must themselves run on a valid stack. For this, the system stack is used.
When the scheduler—running on an M—needs to perform stack management, it switches from the goroutine’s stack to the system stack.
In addition to stack growth and shrinkage, operations like garbage collection and parking a goroutine also require execution on the system stack.
Whenever a thread performs such operation, it switches to the system stack and executes the operation in the context of g0.
Unlike goroutine, threads run scheduler code as soon as M is created, therefore the initial state of M is running.
When M is created or woken up, the scheduler guarantees that there is always an idle processor P so that it can be associated with M to run Go code.
If M is executing system call, it will be detached from P (will be described in Handling System Calls section) and P might be acquired by another thread M1 to continues its work.
If M can’t find a runnable goroutine from its local run queue, the global run queue, or netpoll (will be described in How netpoll Works section), it keeps spinning to steal goroutines from other processors P and from the global run queue again.
Note that not all M enters spinning state, it does so only if the number of spinning threads is less than half of the number of busy processors.
When M has nothing to do, rather than being destroyed, it goes to sleep and waits to be acquired by a another processor P1 later (described in Finding a Runnable Goroutine).
The figure and table below described the state machine of threads in the GMP model. Some states and transitions are omitted for simplicity. Spinning is a substate of idle, in which thread consumes CPU cycles to solely execute Go runtime code that steals goroutine. The actions that trigger state transitions will be described along the post.
| State | Description |
|---|---|
| Running | Executing Go runtime code, or user Go code |
| Syscall | Currently executing (blocking in) a system call |
| Spinning | Stealing goroutine from other processors |
| Sleep | Sleeping, not consuming CPU cycle |
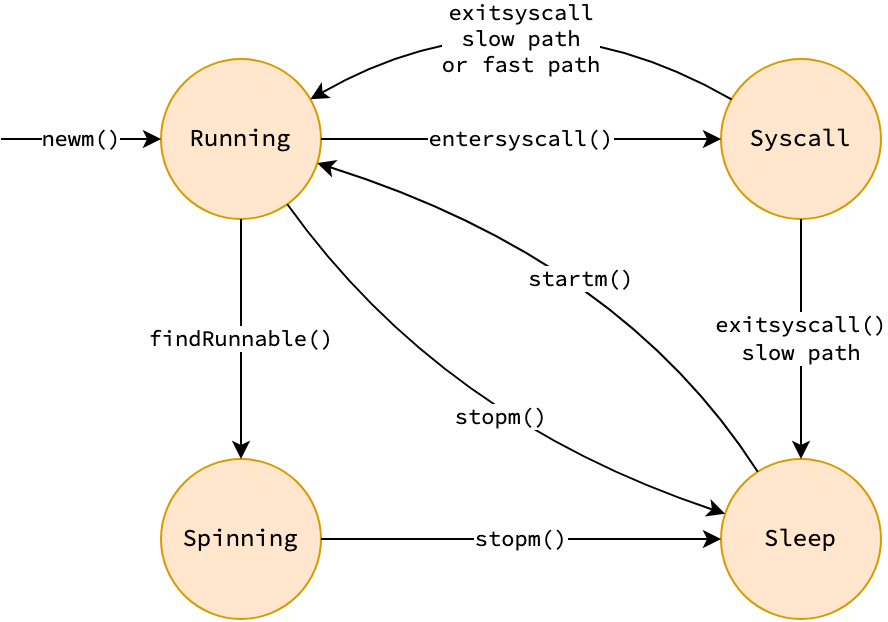 |
|---|
| State machine of threads in GMP model |
Processor: p
p struct conceptually represents a physical processor to execute goroutines.
Instances of p are called P, and they are created during the program’s bootstrap phase.
While the number of threads created could be large (10000 in Go 1.24), the number of processors is usually small and determined by the GOMAXPROCS.
There are exactly GOMAXPROCS processors, regardless of its state.
To minimize lock contention on the global run queue, each processor P in the Go runtime maintains a local run queue.
A local run queue is not just a queue but composed of two components: runnext which holds a single prioritized goroutine, and runq which is a queue of goroutines.
Both of these components serve as a source of runnable goroutines for P, but runnext exists specifically as a performance optimization.
The Go scheduler allows P to steal goroutines from other processors P1’s local run queue.
P1’s runnext in only consulted if the first three attempts stealing from its runq is unsuccessful.
Therefore, when P wants to execute a goroutine, there is less lock contention if it looks for a runnable goroutine from its runnext first.
The runq component of P is an array-based, fixed-size, and circular queue.
By array-based and fixed-size with 256 slots, it allows better cache locality and reduces memory allocation overhead.
Fixed-size is safe for P’s local run queues as we also have the global run queue as a backup.
By circular, it allows efficiently adding and removing goroutines without needing to shift elements around.
mcache serves as the front-end in Thread-Caching Malloc model and is used by P to allocate micro and small objects.
pageCache, on the other hand, enables the memory allocator to fetch memory pages without acquiring the heap lock, thereby improving performance under high concurrency.
In order for a Go program to work well with sleeps, timeouts or intervals, P also manages timers implemented by min-heap data structure, where the nearest timer is at the top of the heap.
When looking for a runnable goroutine, P also checks if there are any timers that have expired.
If so, P adds the corresponding goroutine with timer to its local run queue, giving chance for the goroutine to run.
The figure and table below described the state machine of processors in the GMP model. Some states and transitions are omitted for simplicity. The actions that trigger state transitions will be described along the post.
| State | Description |
|---|---|
| Idle | Not executing Go runtime code or user Go code |
| Running | Associated with a M that is executing user Go code |
| Syscall | Associated with a M that is executing system call |
| GCStop | Associated with a M that is stopped-the-world for garbage collection |
| Dead | No longer in-used, waiting to be reused when GOMAXPROCS grows |
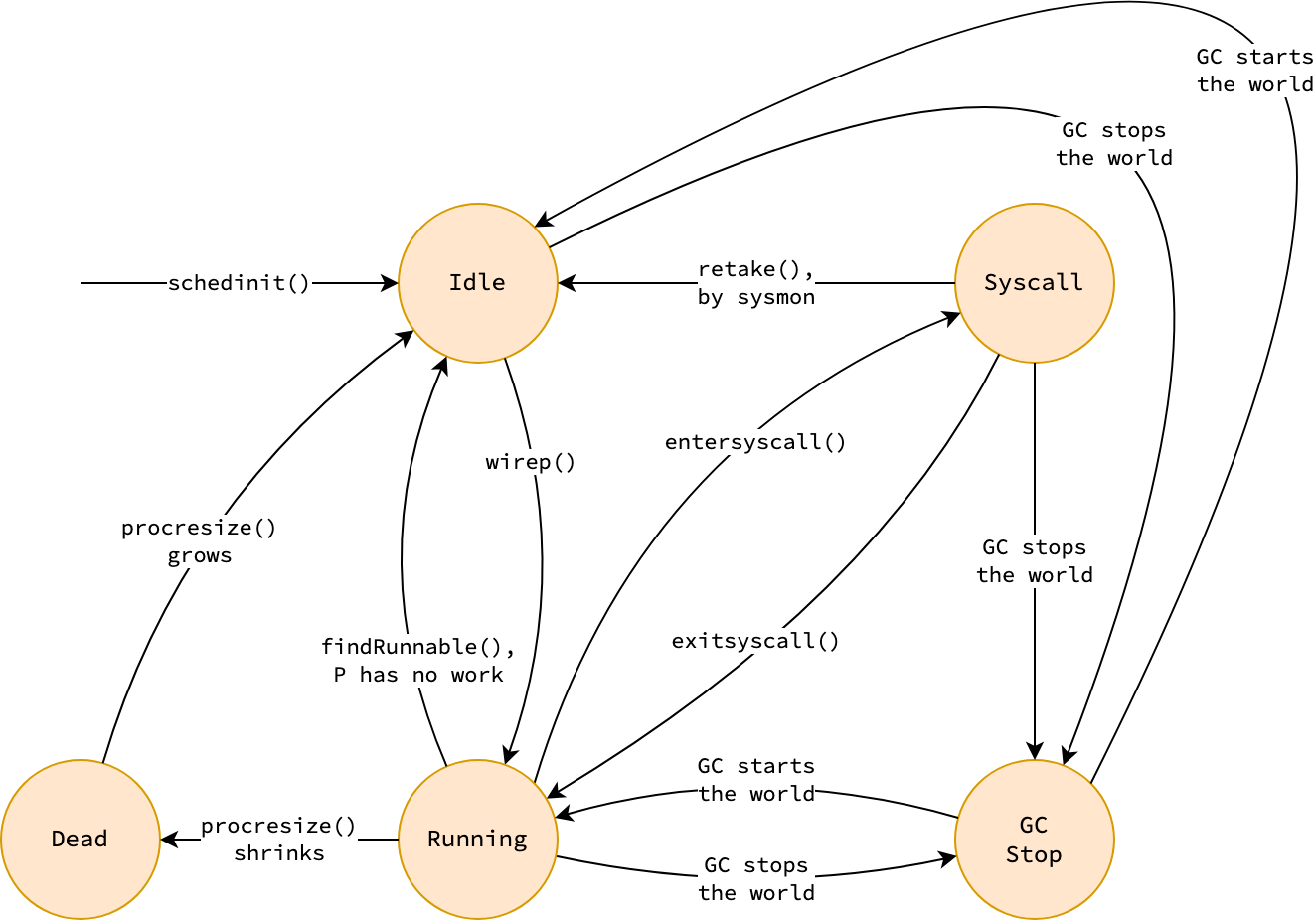 |
|---|
| State machine of processors in GMP model |
At the early execution of a Go program, there are GOMAXPROCS processors P in the idle state.
When a thread M acquires a processor to run user Go code, P transitions to the running state.
If the current goroutine G makes a system call, P is detached from M and enters the syscall state.
During the system call, if P is seized by sysmon (see Non-cooperative Preemption), it first transitions to idle, then is handed off to another thread (M1) and enters the running state.
Otherwise, once the system call completes, P is reattached to last M and resumes the running state (see Handling system calls).
When a stop-the-world garbage collection occurs, P transitions to the gcStop state and returns to its previous state once start-the-world resumes.
If GOMAXPROCS is decreased at runtime, redundant processors transition to the dead state and are reused if GOMAXPROCS increases later.
Program Bootstrap
To enable the Go scheduler, it must be initialized during the program’s bootstrap.
This initialization is handled in assembly via the runtime·rt0_go function.
During this phase, thread M0 (representing the main thread) and goroutine G0 (M0’s system stack goroutine) are created.
Thread-local storage (TLS) for the main thread is also set up, and the address of G0 is stored in this TLS, allowing it to be retrieved later via getg.
The bootstrap process then invokes the assembly function runtime·schedinit, whose Go implementation can be found at runtime.schedinit.
This function performs various initializations, most notably invoking procresize, which sets up to GOMAXPROCS logical processors P in idle state.
The main thread M0 is then associated with the first processors, transitioning its state from idle to running to execute goroutines.
Afterward, the main goroutine is created to run runtime.main function, which serves as the Go runtime entry point.
Within the runtime.main function, a dedicated thread is created to launch sysmon, which will be described in Non-cooperative Preemption section.
Note that runtime.main is different from the main function that we write; the latter appears in the runtime as main_main.
The main thread then calls mstart to begin execution on M0, starting the schedule loop to pick up and execute the main goroutine.
In the runtime.main, after additional initialization steps, control is finally handed off to the user-defined main_main function, where the program begins executing user Go code.
It’s worth noting that the main thread, M0, is responsible not only for running the main goroutine but also for executing other goroutines.
Whenever the main goroutine is blocked—such as waiting for a system call or while waiting on a channel—the main thread looks for another runnable goroutine and execute it.
Summing it up, when the program starts, there is one goroutine G executing the main function; two threads—one is the main thread M0, and the other is created to launch sysmon; one processor P0 in running state, and GOMAXPROCS−1 processors in idle state.
The main thread M0 is initially associated with processor P0 to run the main goroutine G.
The figure below illustrates the program’s state at startup.
It assumes that GOMAXPROCS is set to 2 and that the main function has just started.
Processor P0 is executing the main goroutine and is therefore in running state.
Processor P1 is not executing any goroutine and is in idle state.
While the main thread M0 is associated with processor P0 to execute main goroutine, another thread M1 is created to run sysmon.
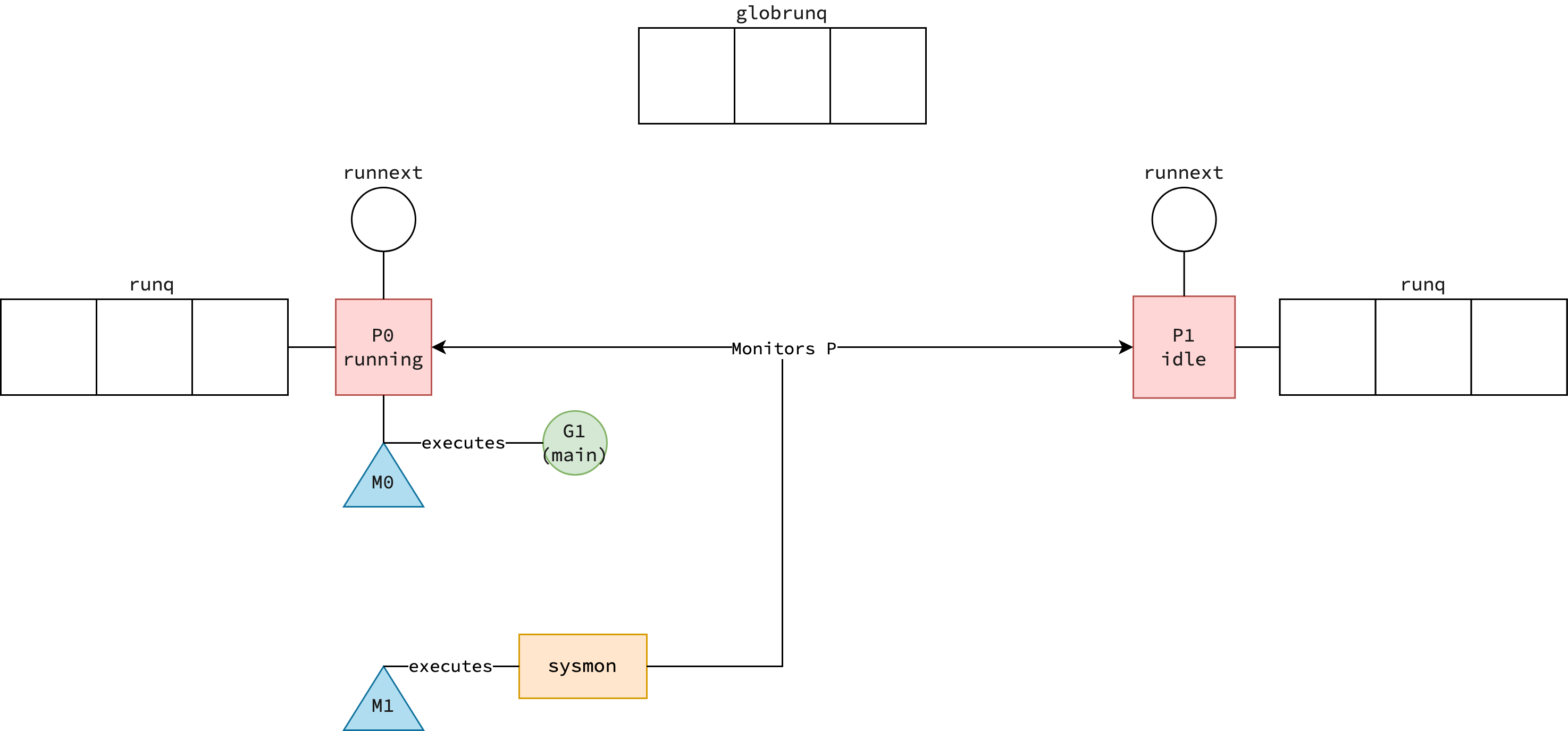 |
|---|
| Program bootstrap in GMP model |
It’s worth to mention that during the bootstrap phase, the runtime also spawns several other goroutines related to memory management, such as marking, sweeping and scavenging. However, we’ll leave those out of scope for this post. They’ll be explored in greater detail in a future article.
Creating a Goroutine
Go offers us a simple API to start a concurrent execution unit: go func() { ... } ().
Under the hood, Go runtime does a lot complicated work to make it happen.
The go keyword is just a syntactic sugar for Go runtime newproc function, which is responsible for scheduling a new goroutine.
This function essentially does 3 things: initialize the goroutine, put it into the run queue of the processor P which the caller goroutine is running on, wake up another processor P1.
Initializing Goroutine
When newproc is called, it creates a new goroutine G only if there are no idle goroutines available.
Goroutines become idle after they return from execution.
The newly created goroutine G is initialized with a 2KB stack, as defined by the stackMin constant in Go runtime.
Additionally, goexit—which handles cleanup logic and scheduling logic—is pushed onto G’s call stack to ensure it is executed when G returns.
After initialization, G transitions from dead state to runnable state, indicating that it’s ready to be scheduled for execution.
Putting Goroutine into Queue
As mentioned earlier, each processor P has a run queue composed of two parts: runnext and runq.
When a new goroutine is created, it is placed in runnext.
If runnext already contains a goroutine G1, the scheduler attempts to move G1 to runq—provided runq is not full—and put G into runnext.
If runq is full, G1 along with half of the goroutines in runq are moved to the global run queue to reduce the workload for P.
Waking Up Processor
When a new goroutine is created, and we aim to maximize program concurrency, the thread which goroutine is running on attempts to wake up another processor P by futex system call.
To do this, it first checks for any idle processors.
If an idle processor P is available, a new thread is either created or an existing one is woken up to enter the schedule loop, where it will look for a runnable goroutine to execute.
The logic for creating or reusing thread is described in Start Thread section.
As previously mentioned, GOMAXPROCS—the number of active processors P—dictates how many goroutines can run concurrently.
If all processors are busy and new goroutines keep spawning, neither existing thread is woken up nor new thread is created.
Putting It All Together
The figure below illustrates the process of how goroutines are created.
For simplicity, it assumes GOMAXPROCS is set to 2, processor P1 hasn’t entered the schedule loop yet, and main function does nothing but keeps spawning new goroutines.
Since goroutines don’t execute system call (discussed in Handling System Calls section), there is exactly one additional thread M2 is created to associate with processor P1.
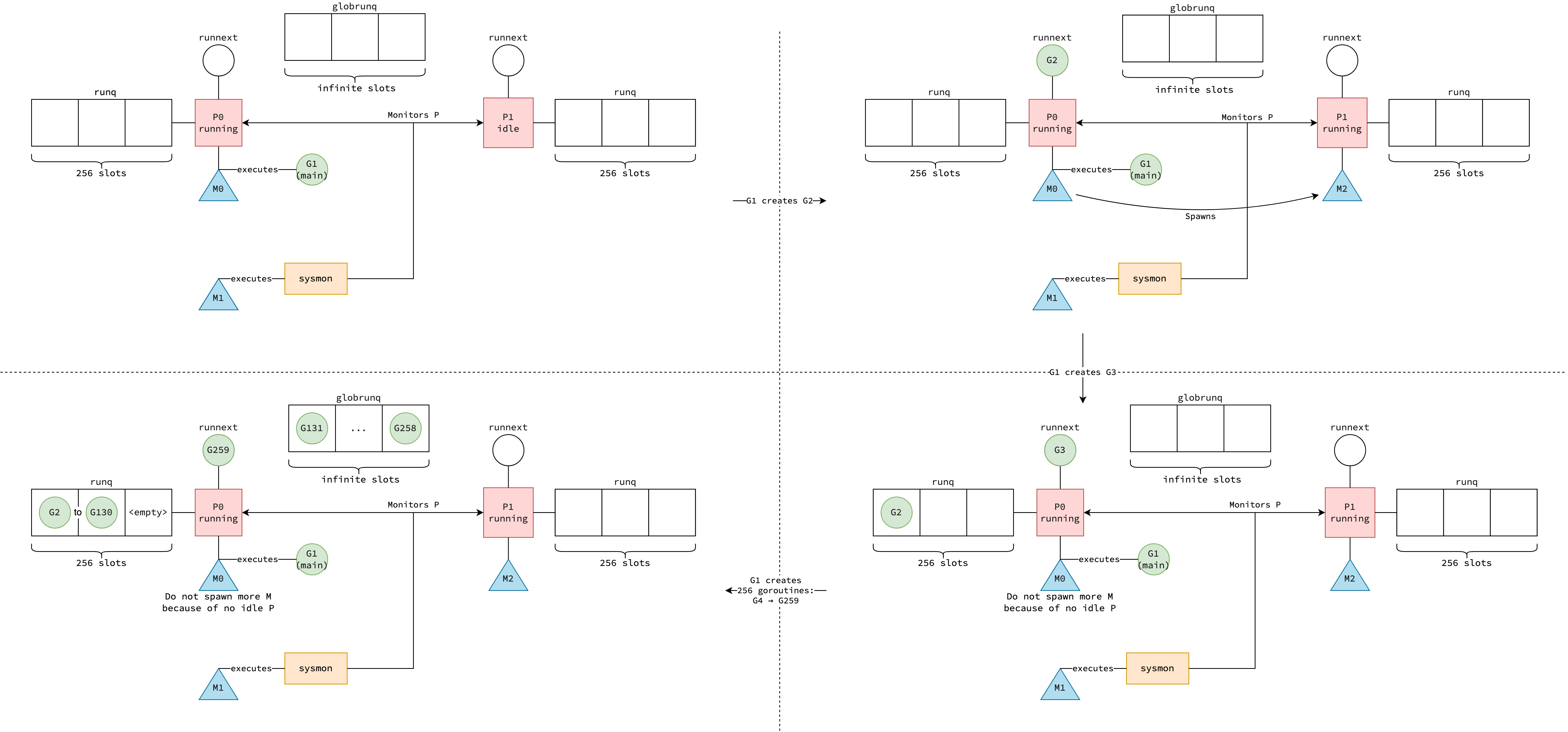 |
|---|
| How goroutines are created in GMP model |
Schedule Loop
The schedule function in the Go runtime is responsible for finding and executing a runnable goroutine.
It is invoked in various scenarios: when a new thread is created, when Gosched is called, when a goroutine is parked or preempted, or after a goroutine completes a system call and returns.
The process of selecting a runnable goroutine is complex and will be detailed in the Finding a Runnable Goroutine section.
Once a goroutine is selected, it transitions from runnable to running state, signaling that it’s ready to run.
At this point, a kernel thread invokes the gogo function to begin goroutine execution.
But why is it called a loop? As described in the Initializing Goroutine section, when a goroutine completes, the goexit function is invoked.
This function eventually leads to a call to goexit0, which performs cleanup for the terminating goroutine and re-enters the schedule function—bringing the schedule loop back.
The following diagram illustrates the schedule loop in Go runtime, where pink blocks happen in user Go code and yellow blocks happen in the Go runtime code. Although the following may seem obvious, please note that the schedule loop is executed by thread. That’s why it happens after thread initialization (the blue block).
graph LR
subgraph Thread_Init[ ]
newm["newm()"] ==> mstart["mstart()"]
mstart ==> mstart0["mstart0()"]
mstart0 ==> mstart1["mstart1()"]
end
mstart1 ==> schedule["schedule()"]
schedule ==> findrunnable["findrunnable()
|
| The schedule loop in Go runtime |
But if the main thread is stuck in schedule loop, how can the process exit?
Just take a look at the main function in Go runtime, which is executed by main goroutine.
After main_main—alias of the main function that Go programmers write—returns, exit system call is invoked to terminate the process.
That’s how the process can exit and the reason why the main goroutine doesn’t wait for goroutines spawned by go keyword.
Finding a Runnable Goroutine
It is the thread M’s responsibility to find a suitable runnable goroutine so that goroutine starvation can be minimized.
This logic is implemented in the findRunnable, which is called by the schedule loop.
Thread M looks for a runnable goroutine the following order, stopping the chain if it finds one:
- Check trace reader goroutine’s availability (used in Non-cooperative Preemption section).
- Check garbage collection worker goroutine’s availability (described in Garbage Collector section).
- 1/61 of the time, check the global run queue.
- Check local run queue of the associated processor
PifMis spinning. - Check the global run queue again.
- Check netpoll for I/O ready goroutine (described in How netpoll Works section).
- Steal from other processors
P1’s local run queue. - Check garbage collection worker goroutine’s availability again.
- Check the global run queue again if
Mis spinning.
Step 1, 2 and 8 are for Go runtime internal use only. In step 1, trace reader is used for tracing the execution of the program. You will see how it’s used in the Goroutine Preemption section later. Meanwhile, step 2 and 8 allow the garbage collector to run concurrently with the regular goroutines. Although these steps don’t contribute to “user-visible” progress, they are essential for the Go runtime to function properly.
Step 3, 5 and 9 don’t just take one goroutine but attempts to grab a batch for better efficiency.
The batch size is calculated as (global_queue_size/number_of_processors)+1, but it’s limited by several factors: it won’t exceed the specified maximum parameter, and won’t take more than half of the P’s local queue capacity.
After determining how many to take, it pops one goroutine to return directly (which will be run immediately) and puts the rest into the P’s local run queue.
This batching approach helps with load balancing across processors and reduces contention on the global queue lock, as processors don’t need to access the global queue as frequently.
Step 4 is a bit more tricky because the local run queue of P contains two parts: runnext and runq.
If runnext is not empty, it returns the goroutine in runnext.
Otherwise, it checks runq for any runnable goroutine and dequeue it.
Step 6 will be described in detail in How netpoll Works section.
Step 7 is the most complex part of the process.
It attempts up to four times to steal work from another processor, referred to as P1.
During the first three attempts, it tries to steal goroutines only from P1’s runq.
If successful, half of the goroutines from P1’s runq are transferred to the current processor P’s runq.
On the last attempt, it first tries to steal from P1’s runnext slot—if available—before falling back to P1’s runq.
Note that findRunnable not only finds a runnable goroutine but also wakes up goroutine that went into sleep before step 1 happens.
Once the goroutine wakes up, it’ll be put into the local run queue of the processor P that was executing it, waiting to be picked up and executed by some thread M.
If no goroutine is found after step 9, thread M waits on netpoll until the nearest timer expires—such as when a goroutine wakes up from sleep (since sleeping in Go internally creates a timer).
Why is netpoll involved with timers? This is because Go’s timer system heavily relies on netpoll, as noted in this code comment.
After netpoll returns, M re-enters the schedule loop to search for a runnable goroutine again.
The previous two behaviors of findRunnable allows the Go scheduler to wake up asleep goroutines, allowing the program to continue executing.
They explain why every goroutine including the main one has chance to run after falling asleep.
Let’s see how the following Go program works in another post 😄.
package main
import "time"
func main() {
go func() {
time.Sleep(time.Second)
}()
time.Sleep(2*time.Second)
}
If P has no timer, its corresponding thread M will go idle.
P is placed into idle list, M goes to sleep by calling the stopm function.
It remains asleep until another M1 thread wakes it up, typically upon the creation of a new goroutine, as explained in Waking Up Processor.
Once awakened, M reenters the schedule loop to search for and execute a runnable goroutine.
Goroutine Preemption
Preemption is the act of temporarily interrupting a goroutine execution to allow other goroutines to run, preventing goroutine starvation. There are two types of preemption in Go:
- Non-cooperative preemption: a too long-running goroutine is forced to stop.
- Cooperative preemption: a goroutine voluntarily yields its processor
P.
Let’s see how these two types of preemption work in Go.
Non-cooperative Preemption
Let’s take an example to understand how non-cooperative preemption works.
In this program, we have two goroutines that calculate the Fibonacci number, which is a tight loop with CPU intensive operations.
In order to make sure that only one goroutine can run at a time, we set the maximum number of logical processors to 1 using GOMAXPROCS when running the program: GOMAXPROCS=1 go run main.go.
package main
import (
"runtime"
"time"
)
func fibonacci(n int) int {
if n <= 1 {
return n
}
previous, current := 0, 1
for i := 2; i <= n; i++ {
previous, current = current, previous+current
}
return current
}
func main() {
go fibonacci(1_000_000_000)
go fibonacci(2_000_000_000)
time.Sleep(3*time.Second)
}
Because there is exactly one processor P, there are many cases that could happen.
One, neither goroutine runs because the main function has taken control of P.
Two, one goroutine runs while the other is starved of execution.
Three, somehow both goroutines run concurrently—almost magically.
Fortunately, Go does support us to get the idea of what is happening with the scheduling.
The runtime/trace package contains a powerful tool for understanding and troubleshooting Go programs.
To use it, we need to add instrument to the main method to export the traces to file.
func main() {
file, _ := os.Create("trace.out")
_ = trace.Start(file)
defer trace.Stop()
...
}
After the program finishes running, we use the command go tool trace trace.out to visualize the trace.
I have prepared the trace.out file here just in case you want to play with it.
In the figure below, the horizontal axis represents which goroutine is running on P at a given time.
As expected, there is only one logical processor P named “Proc 0”, resulted from GOMAXPROCS=1.
 |
|---|
| Trace visualization when program starts |
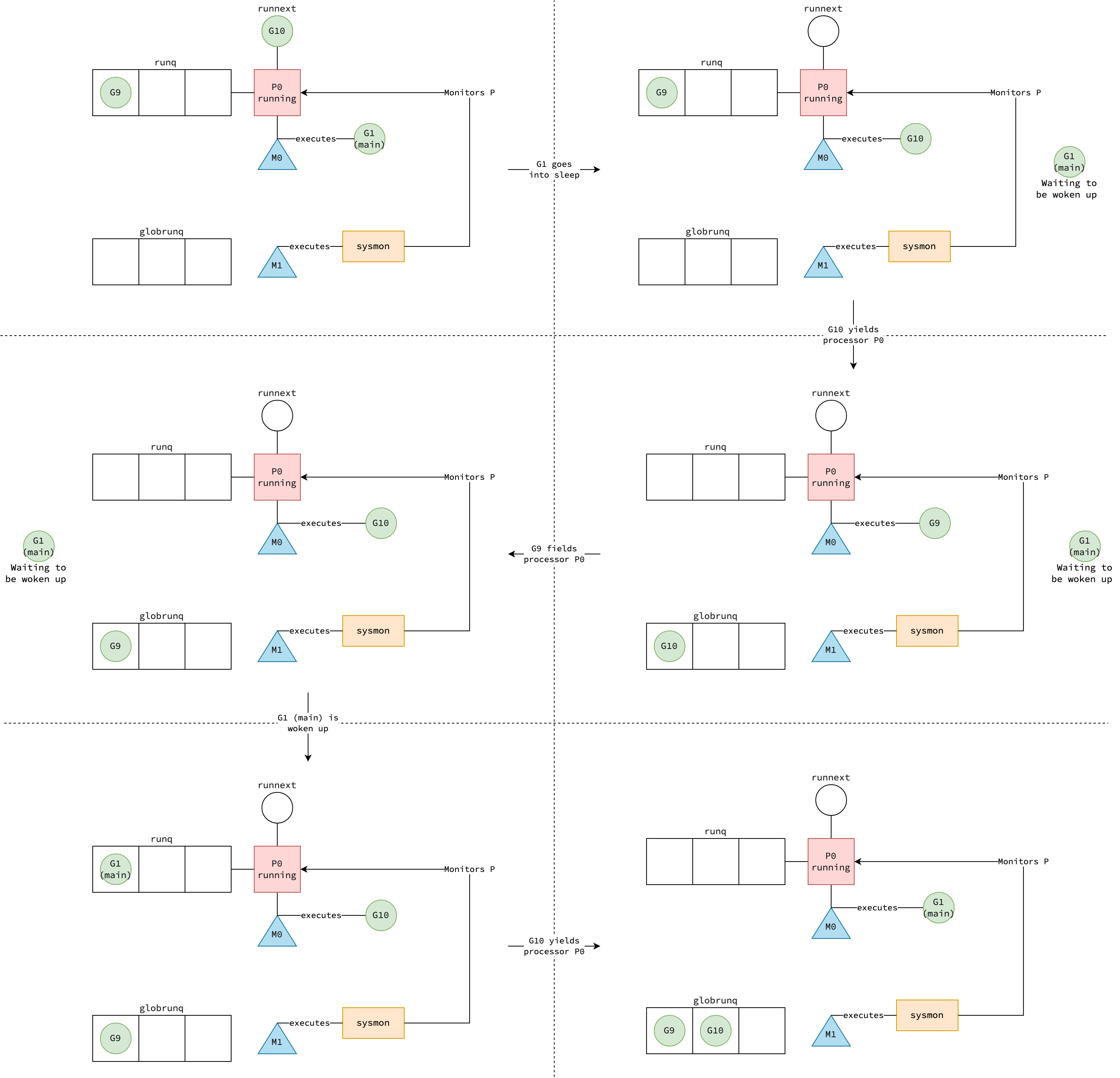
By zooming in (pressing ‘W’) to the start of the timeline, you can see that the process begins with main.main (the main function in the main package), which runs on the main goroutine, G1.
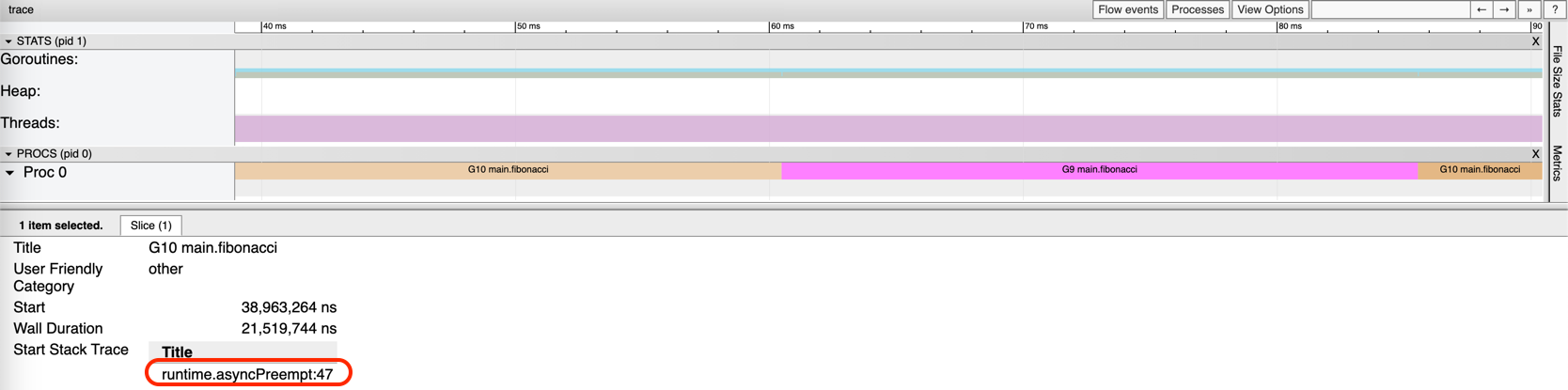
After a few microseconds, still on Proc 0, goroutine G10 is scheduled to execute the fibonacci function, taking over the processor and preempting G1.
 |
|---|
| Trace visualization when non-cooperative preemption happens |
By zooming out (pressing ‘S’) and scrolling slightly to the right, it can be observed that G10 is later replaced by another goroutine, G9, which is the next instance running the fibonacci function.
This goroutine is also executed on Proc 0. Pay attention to runtime.asyncPreempt:47 in the figure, I will explain this in a moment.
From the demo, it can be concluded that the Go is capable of preempting goroutines that are CPU-bound. But why is it possible because if a goroutines continuously taking up the CPU, how can it be preempted? This is a hard problem and there was a long discussion on the Go issue tracker. The problem was not addressed until Go 1.14, where asynchronous preemption was firstly introduced.
In Go runtime, there is a daemon running on a dedicated thread M without a P, called sysmon (i.e. system monitor).
When sysmon finds a goroutine that has been using P for more than 10ms (forcePreemptNS constant in Go runtime), it signals thread M by executing tgkill system call to forcefully preempt the running goroutine.
Yes, you didn’t read that wrong. According to the Linux manual page, tgkill is used to send a signal to a thread, not to kill a thread.
The signal is SIGURG, and the reason it being chosen is described here.
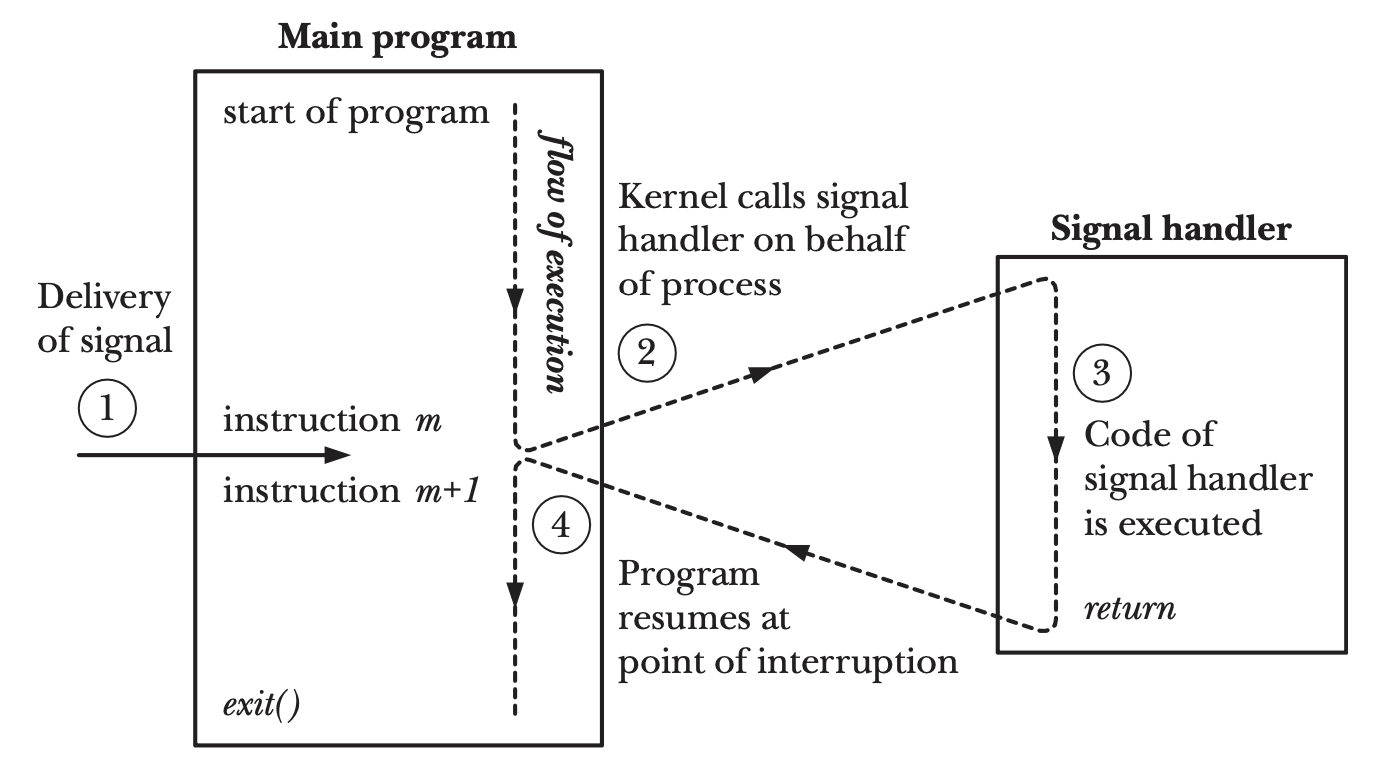
Upon receiving SIGURG, the execution of the program is transferred to the signal handler, registered by a call of initsig function upon thread initialization.
Note that the signal handler can run concurrently with goroutine code or the scheduler code, as depicted in the figure below.
The execution switch from main program to signal handler is triggered by the kernel4,5.
 |
|---|
| Signal delivery and handler execution6 |
In the signal handler, the program counter is set to the asyncPreempt function, allowing the goroutine to be suspended and creating space for preemption.
In the assembly implementation of asyncPreempt function, it saves the goroutine’s registers and call asyncPreempt2 function at line 47.
That is reason for the appearance of runtime.asyncPreempt:47 in the visualization.
In asyncPreempt2, the goroutine g0 of thread M will enter gopreempt_m to disassociate goroutine G from M and enqueue G into the global run queue.
The thread then continues with the schedule loop, finding another runnable goroutine and execute it.
As preemption signal is triggered by sysmon but the actual preemption doesn’t happen until the thread receives preemption signal, this kind of preemption is asynchronous.
That’s why goroutines can actually run beyond the time limit 10ms, like goroutine G9 in the example.
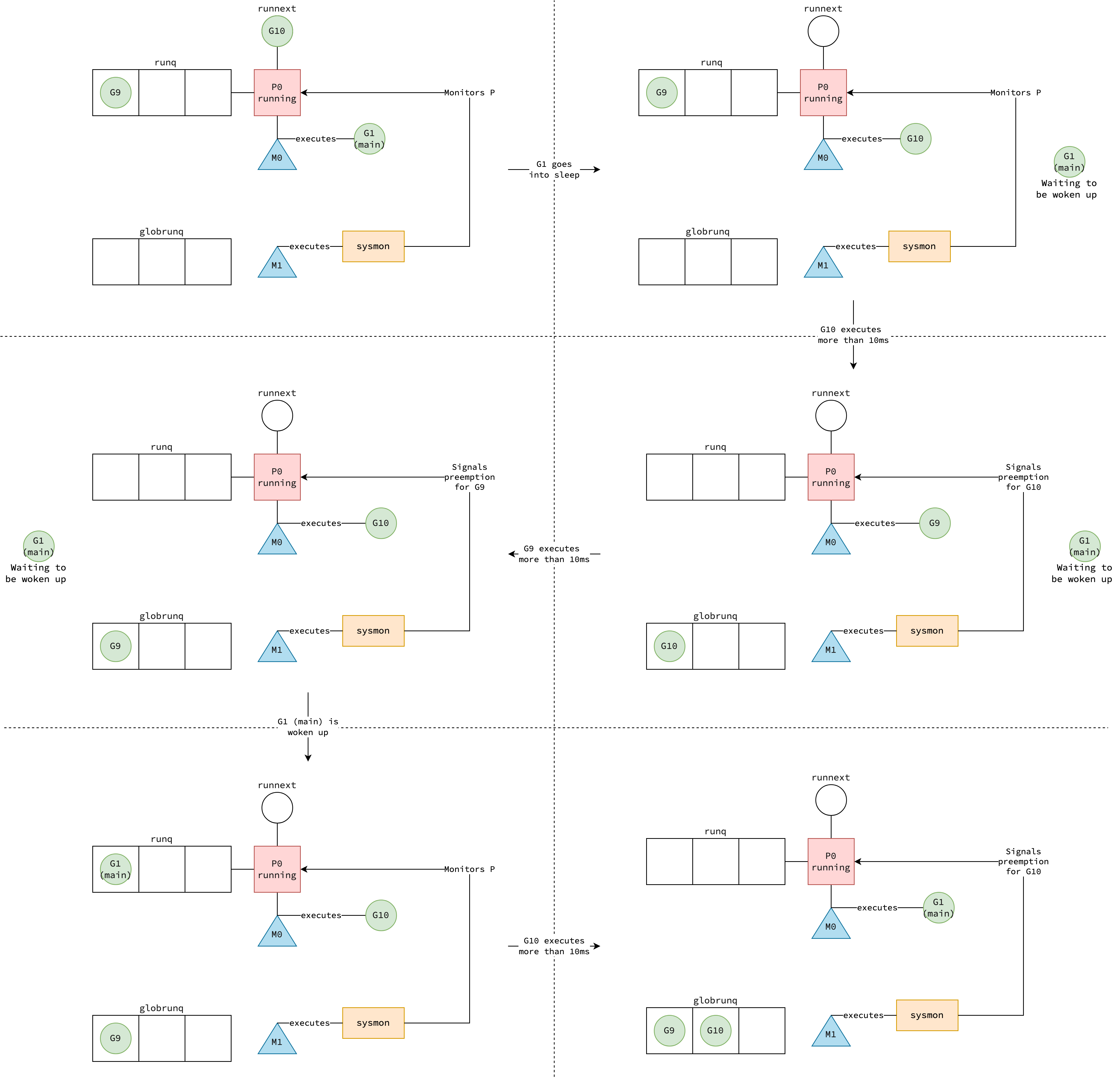 |
|---|
| Non-cooperative preemption in GMP model |
Cooperative Preemption in Early Go
In the early days of Go, Go runtime itself was not able to preempt a goroutines that have tight loop like the example above.
We, as Go programmers, had to tell goroutines to cooperatively give up its processor P by making a call to runtime.Gosched() in the loop body.
There was a Stackoverflow question that described an example and the behavior of runtime.Gosched().
From the programmer’s point of view, this is very tedious and error-prone, and it did have some performance issue in actuality. Therefore, the Go team has decided to implement a clever way to preempt the goroutine by the runtime itself. This will be discussed in the next section.
Cooperative Preemption Since Go 1.14
Do you wonder why I didn’t use fmt.Printf in each iteration and check the terminal to see whether both goroutines have chance to run?
That’s because if I had done that, it would have become a cooperative preemption, not a non-cooperative preemption anymore.
Disassemble the Program
To better understand this, let’s compile the program and analyze its assembly code.
Since the Go compiler applies various optimizations that can make debugging more challenging, we need to disable them when building the program.
This can be done by go build -gcflags="all=-N -l" -o fibonacci main.go.
For easier debugging, I use Delve, a powerful debugger for Go, to disassemble the fibonacci function: dlv exec ./fibonacci.
Once inside the debugger, I run the following command to view the assembly code of the fibonacci function: disassemble -l main.fibonacci.
You can find the assembly code of the original program here.
As I’m building the program on my local machine, which is darwin/arm64, the assembly code built on your machine could be different from mine.
That’s all set, let’s take a look at the assembly of the fibonacci function to see what it does.
main.go:11 0x1023e8890 900b40f9 MOVD 16(R28), R16
main.go:11 0x1023e8894 f1c300d1 SUB $48, RSP, R17
main.go:11 0x1023e8898 3f0210eb CMP R16, R17
main.go:11 0x1023e889c 090c0054 BLS 96(PC)
...
main.go:17 0x1023e8910 6078fd97 CALL runtime.convT64(SB)
...
main.go:17 0x1023e895c 4d78fd97 CALL runtime.convT64(SB)
...
main.go:20 0x1023e8a18 c0035fd6 RET
main.go:11 0x1023e8a1c e00700f9 MOVD R0, 8(RSP)
main.go:11 0x1023e8a20 e3031eaa MOVD R30, R3
main.go:11 0x1023e8a24 dbe7fe97 CALL runtime.morestack_noctxt(SB)
main.go:11 0x1023e8a28 e00740f9 MOVD 8(RSP), R0
main.go:11 0x1023e8a2c 99ffff17 JMP main.fibonacci(SB)
MOVD 16(R28), R16 loads the value at offset 16 from the register R28, which holds the goroutine data structure g, and store that value in register R16.
The loaded value is the stackguard0 field, which serves as the stack guard for the current goroutine.
But what exactly is a stack guard? You may know that a goroutine’s stack is growable, but how does Go runtime determine when it needs to grow?
The stack guard is a special value placed at the end of the stack. When the stack pointer reaches this value, Go runtime detects that the stack is nearly full and needs to grow—that’s exactly what the next three instructions do.
SUB $48, RSP, R17 loads the goroutine’s stack pointer from the register RPS to register R17 and subtracts 48 from it.
CMP R16, R17 compares the stack guard with the stack pointer, and BLS 96(PC) branches to the instruction located 96 instructions ahead in the program if the stack pointer is less than or equal to the stack guard.
Why less than or equal (≤) but not greater or equal (≥)?
Because stack grows downward, the stack pointer is always greater than the stack guard.
Have you ever wondered why these instructions don’t appear in the Go code but still show up in the assembly?
That’s because upon compiling, Go compiler automatically inserts these instructions in function prologue.
This applies for every function like fmt.Println, not just our fibonacci.
After advancing 96 instructions, execution reaches the MOVD R0, 8(RSP) instruction and then proceeds to CALL runtime.morestack_noctxt(SB).
runtime.morestack_noctxt function will eventually call newstack to grow the stack and optionally enter gopreempt_m to trigger preemption as discussed in non-cooperative preemption.
The key point of cooperative preemption is the condition for entering gopreempt_m, which is stackguard0 == stackPreempt.
This means that whenever a goroutine wants to extend its stack, it will be preempted if its stackguard0 was set to stackPreempt earlier.
stackPreempt can be set by the sysmon if a goroutine has been running for more than 10ms.
The goroutine will then be cooperatively preempted if it makes a function call or non-cooperatively preempted by the thread’s signal handler, whichever happens first.
It can also be set when the goroutine enters or exits a system call or during the tracing phase of the garbage collector.
See sysmon preemption, syscall entry/exit, garbage collector tracing.
Trace Visualization
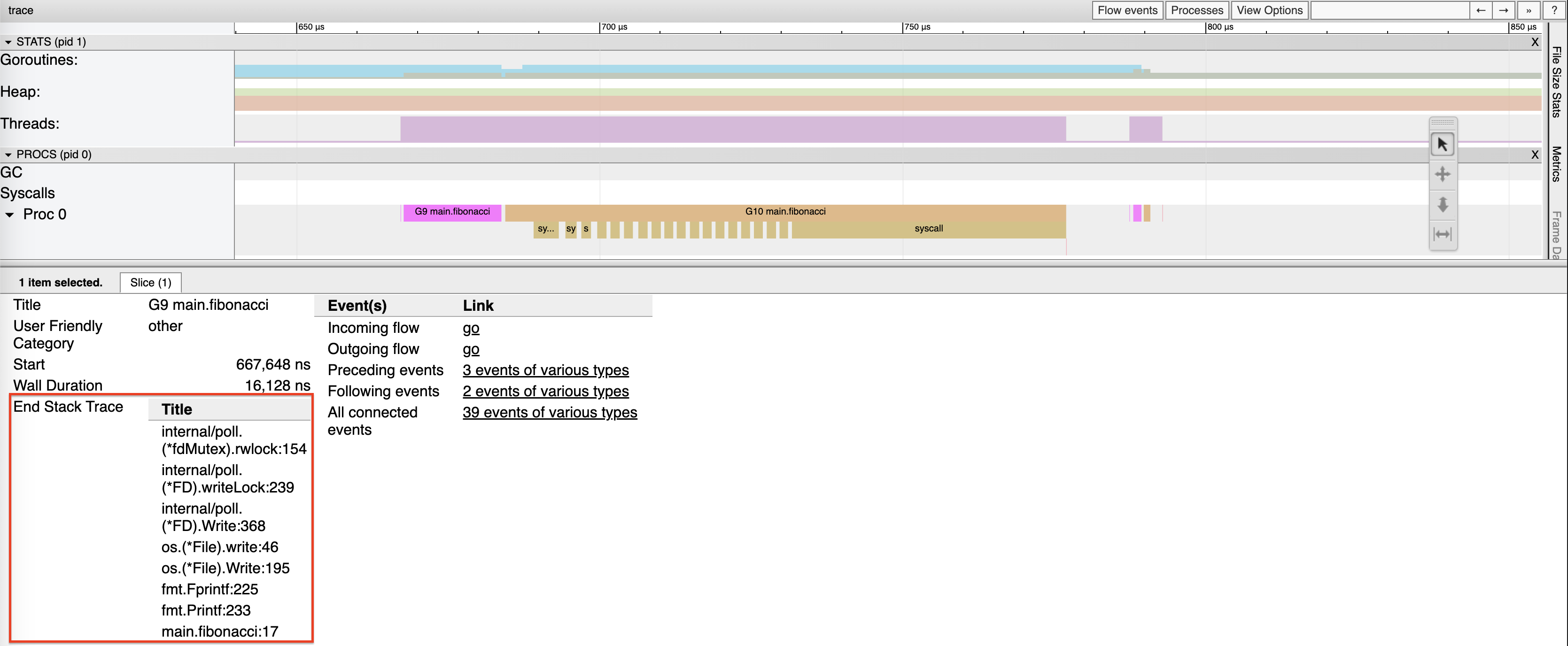
Alright, let’s rerun the program—make sure GOMAXPROCS=1 is set—and then check out the trace.
 |
|---|
| Trace visualization when cooperative preemption happens |
You can clearly see that goroutines relinquish the logical processor after just tens of microseconds—unlike with non-cooperative preemption, where they might retain it for over 10 milliseconds.
Notably, G9’s stack trace ends at the fmt.Printf inside the loop body, demonstrating the stack guard check in function prologue.
This visualization precisely illustrates cooperative preemption, where goroutines voluntarily yield the processor.
 |
|---|
| Cooperative preemption in GMP model |
Handling System Calls
System calls are services provided by the kernel that user-space applications access through an API. These services include fundamental operations, for example, reading files, establishing connections, or allocating memory. In Go, you rarely need to interact with system calls directly, as the standard library offers higher-level abstractions that simplify these tasks.
However, understanding how system calls work is crucial to gaining insight into Go runtime, standard library internals, as well as performance optimization.
Go’s runtime employs an M:N threading model, further optimized by the use of logical processors P, making its approach to handling system calls particularly interesting.
System Call Classification
In Go runtime, there are two wrapper functions around kernel system calls: RawSyscall and Syscall.
The Go code we write uses these functions to invoke system calls. Each function accepts a system call number, its arguments, and returns values along with an error code.
Syscall is typically used for operations with unpredictable durations, such as reading from a file or writing an HTTP response.
Since the duration of these operations is non-deterministic, Go runtime needs to account for them to ensure efficient use of resources.
The function coordinates goroutines G, threads M, and processors P, allowing the Go runtime to maintain performance and responsiveness during blocking system calls.
Nevertheless, not all system calls are unpredictable. For example, retrieving the process ID or getting the current time is usually quick and consistent. For these types of operations, RawSyscall is used.
Since no scheduling is involved, the association between goroutines G, threads M, and processors P remains intact when raw system calls are made.
Internally, Syscall delegates to RawSyscall to perform the actual system call, but wraps it with additional scheduling logic, which will be described in detail in the next section.
func Syscall(trap, a1, a2, a3 uintptr) (r1, r2 uintptr, err Errno) {
runtime_entersyscall()
r1, r2, err = RawSyscall6(trap, a1, a2, a3, 0, 0, 0)
runtime_exitsyscall()
}
Scheduling in Syscall
The scheduling logic is implemented in runtime_entersyscall function and runtime_exitsyscall function, respectively before and after actual system call is made.
Under the hood, these functions are actually runtime.entersyscall and runtime.exitsyscall.
This association are created at compile time.
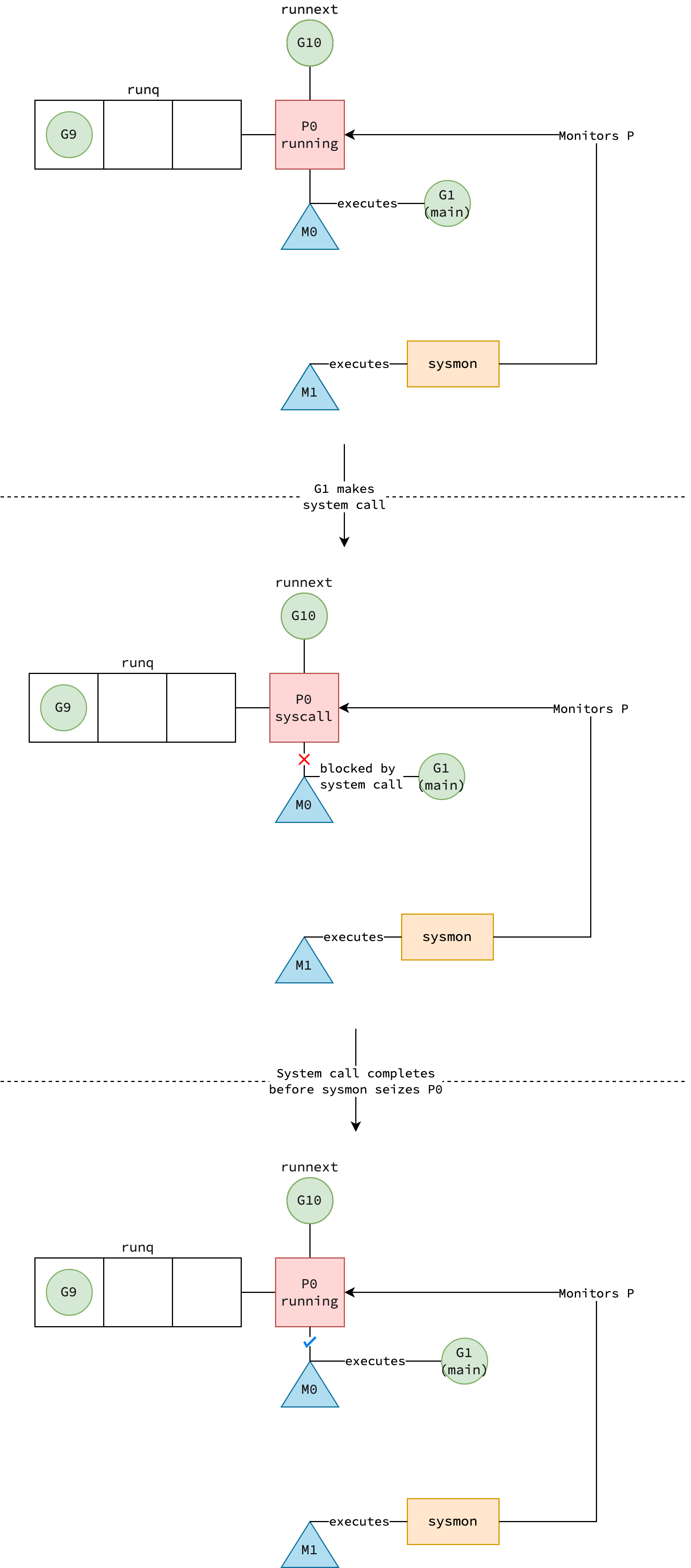
Before an actual system call is made, Go runtime records that the invoking goroutine is no longer using the CPU.
The goroutine G transitions from running state to syscall state, and its stack pointer, program counter, and frame pointer are saved for later restoration.
The association between thread M and processor P is then temporarily detached, and P transitions to syscall state.
This logic is implemented in the runtime.reentersyscall, which is invoked by runtime.entersyscall.
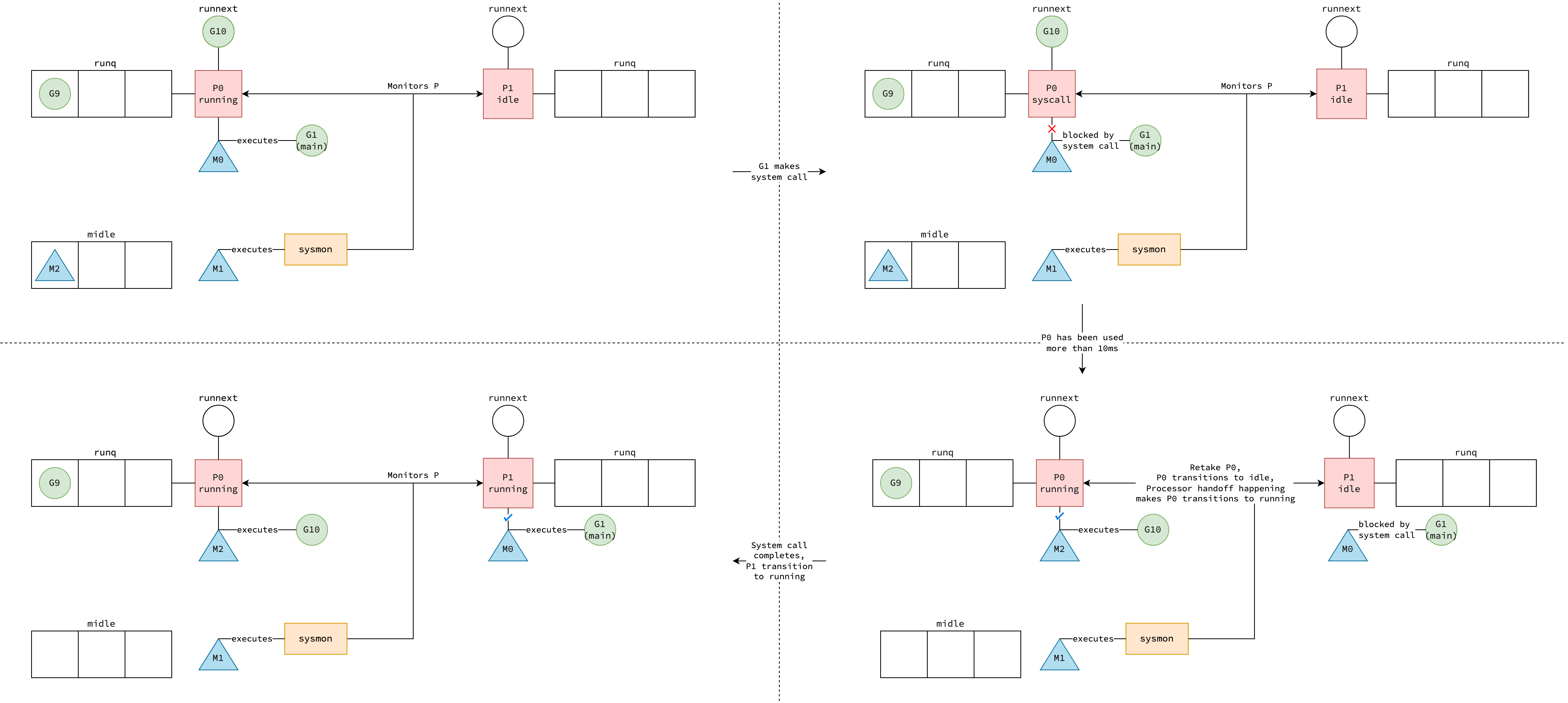
Interestingly, the sysmon (mentioned in the Non-cooperative Preemption section) monitors not only processors running goroutine code (where P is in running state), but also those making system calls (where P is in syscall state).
If a P remains in syscall state for more than 10ms, instead of non-cooperatively preempting the running goroutine, a processor handoff takes place.
This keeps the association between goroutine G and thread M, and attaches another thread M1 to this P, allowing runnable goroutines to run on that M1 thread.
Apparently, as P is now executing code, its status is running rather than syscall as before.
Note that while system call is still in progress and whether sysmon happens to seize P or not, the association between goroutine G and thread M still remains.
Why? Because the Go program (including Go runtime and Go code we write) are just user-space process.
The only mean of execution that kernel provides user-space process is thread.
It is the responsibility of thread to run Go runtime code, user Go code and make system call.
A thread M makes system call on behalf of some goroutine G, that’s why the association between them is maintained as-is.
Therefore, even if P is seized by sysmon, M remains blocked, waiting for the system call to complete before it can invoke the runtime.exitsyscall function.
Another important point is that whenever a processor P is in syscall state, it can't be taken up by another thread M to execute code until sysmon happens to seize it or until the system call is completed.
Therefore, in case there are multiple system calls happening at the same time, the program (excluding system calls) doesn’t make any progress.
That’s why Dgraph database hardcodes GOMAXPROCS to 128 to “allow more disk I/O calls to be scheduled”.
As described in runtime.exitsyscall, there are two paths the scheduler can take after the syscall is finished: fast path and slow path.
The latter only takes place if the former is not possible.
The fast path occurs when if is a processor P available to execute the goroutine G that has just completed its system call.
This P can either be the same one that previously executed G, if it is still in the syscall state (i.e., it hasn’t been seized by sysmon), or any other processor P1 currently in the idle state—whichever is found first.
Note that when system call completes, the previous process P might not be in syscall state anymore bcause sysmon has seized it.
Before the fast path exits, G transition from syscall state to running state.
 |
 |
|---|---|
System call fast path when sysmon doesn’t seize processor P |
System call fast path when sysmon seizes processor P |
In the slow path, the scheduler tries retrieving any idle processor P once again.
If it’s found, the goroutine G is scheduled to run on that P.
Otherwise, G is enqueued into the global run queue and the associated thread M is stopped by stopm function, waiting to be woken up to continue the schedule loop.
Network I/O and File I/O
This survey shows that 75% of Go uses cases are web services and 45% are static websites. It’s not a coincidence, Go is designed to be efficient for I/O operations to solve the notorious problem—C10K. To see how Go solves it, let’s take a look at how Go handles I/O operations under the hood.
{kind=link}
HTTP Server Under the Hood
In Go, it’s incredibly straightforward to start an HTTP server. For example:
package main
import "net/http"
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(200)
})
http.ListenAndServe(":80", nil)
}
Functions like http.ListenAndServe() and http.HandleFunc() might seem deceptively simple—but under the hood, they abstract away a lot of low-level networking complexity.
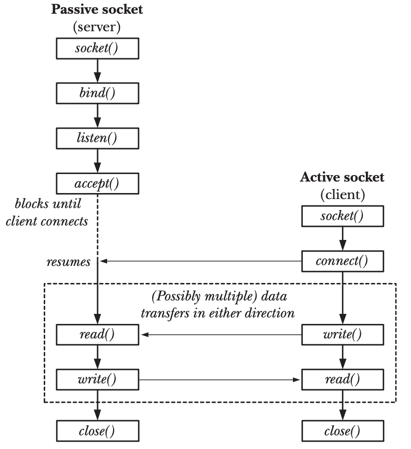
Go relies on many fundamental socket operations (depicted in the figure below) to manage network communication.
 |
|---|
| Overview of system calls used with stream sockets7 |
Specifically, http.ListenAndServe() leverages socket(), bind(), listen(), accept() system calls to create TCP sockets, which are essentially file descriptors.
It binds the TCP listening socket to the specified address and port, listens for incoming connections, and creates a new connected socket to handle client requests.
This is achieved without requiring you to write socket-handling code.
Similarly, http.HandleFunc() registers your handler functions, abstracting away the lower-level details like using read() system call to read data, and write() system call to write data to the network socket.
 |
|---|
| Go abstracts system calls to provide simple interface for HTTP server |
However, it’s not that simple for an HTTP server to handle tens of thousands of concurrent requests efficiently. Go employs several techniques to achieve this. Let’s take a closer look at some notable I/O models in Linux and how Go takes advantage of them.
Blocking I/O, Non-blocking I/O and I/O Multiplexing
An I/O operation can be either blocking or non-blocking.
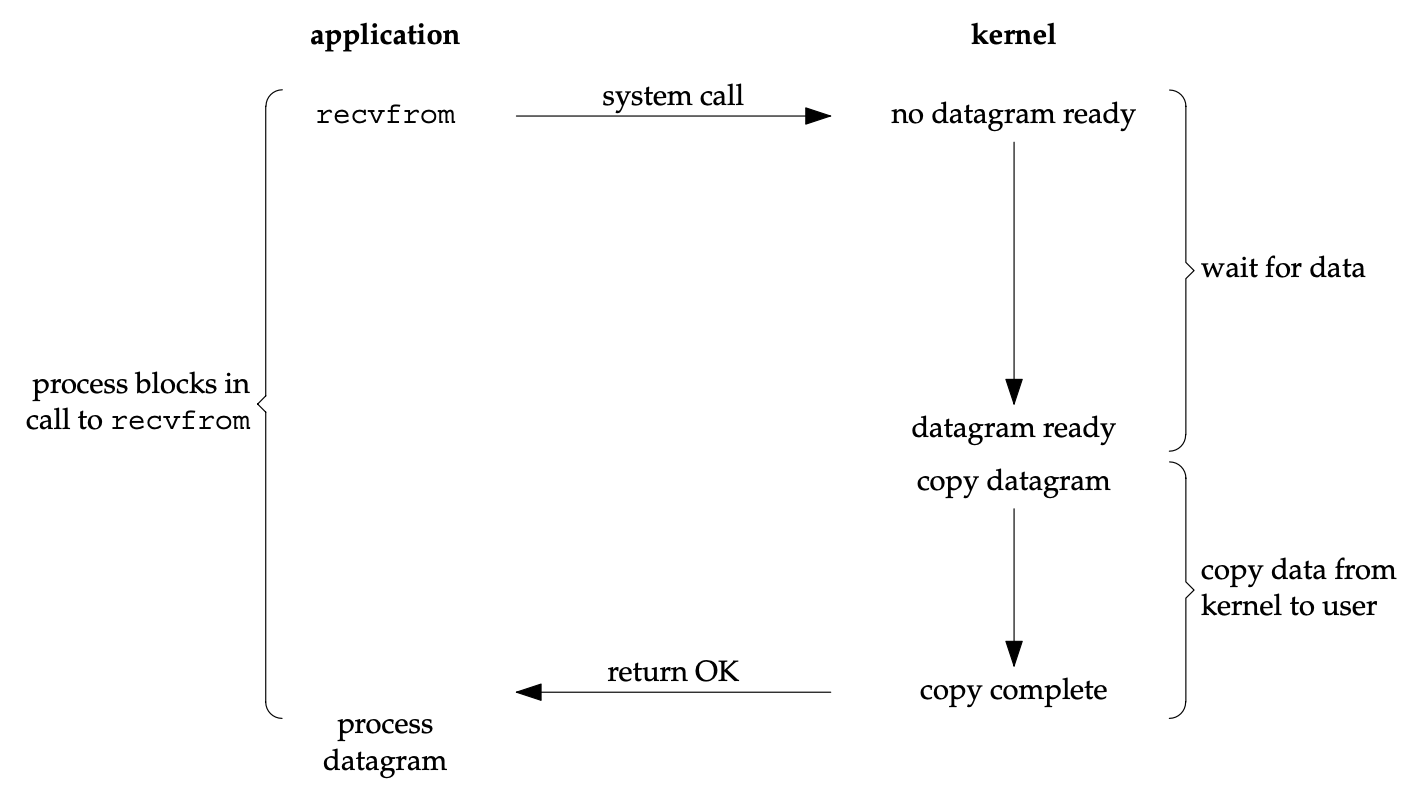
When a thread issues a blocking system call, its execution is suspended until the system call completes with the requested data.
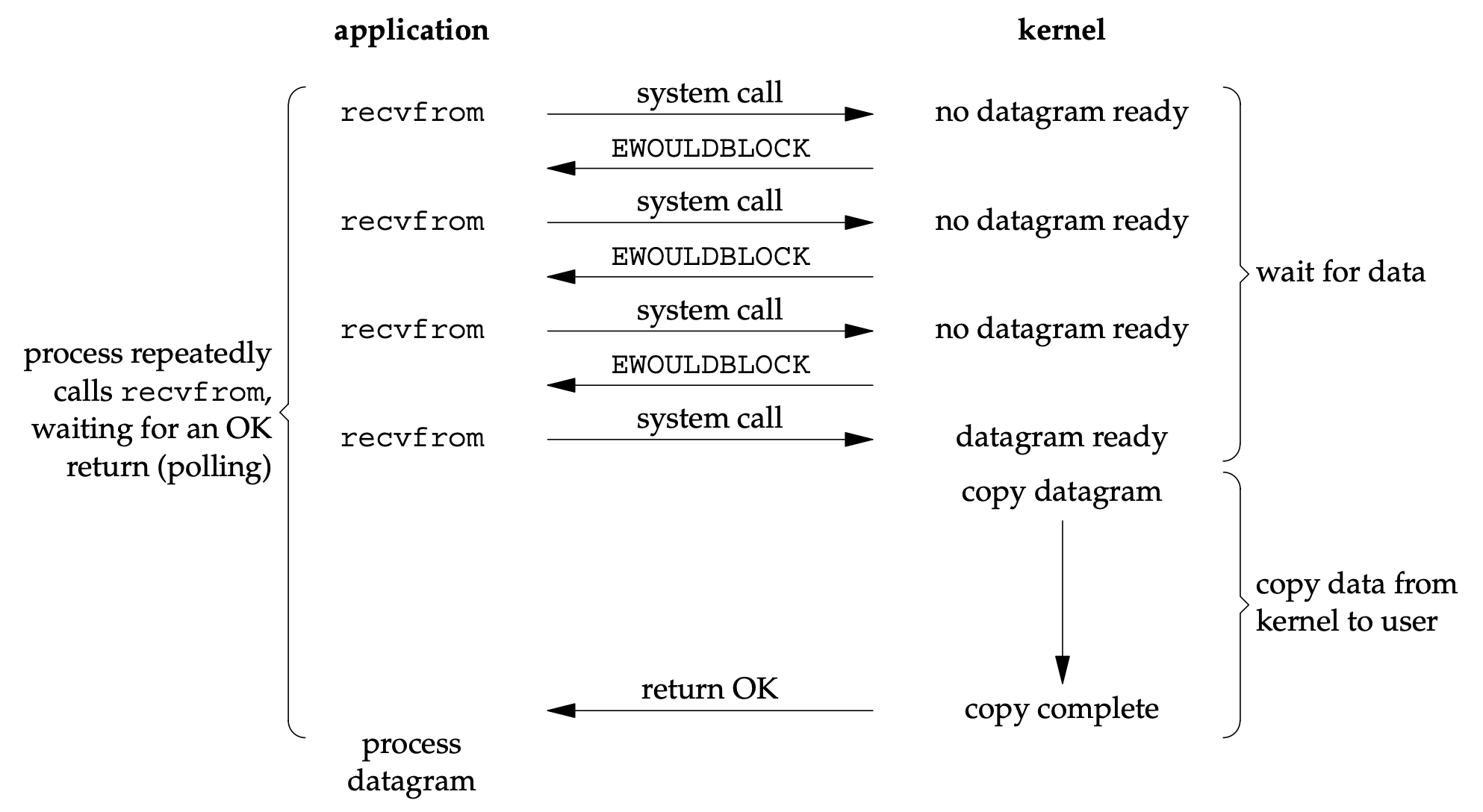
In contrast, non-blocking I/O doesn’t suspend the thread; instead, it returns the requested data if available, or an error (EAGAIN or EWOULDBLOCK) if the data is not yet ready.
Blocking I/O is simpler to implement but inefficient, as it requires the application to spawn N threads for N connections.
In contrast, non-blocking I/O is more complex, but when implemented correctly, it enables significantly better resource utilization.
See the figures below for a visual comparison of these two models.
 |
 |
|---|---|
| Blocking I/O model8 | Non-blocking I/O model9 |
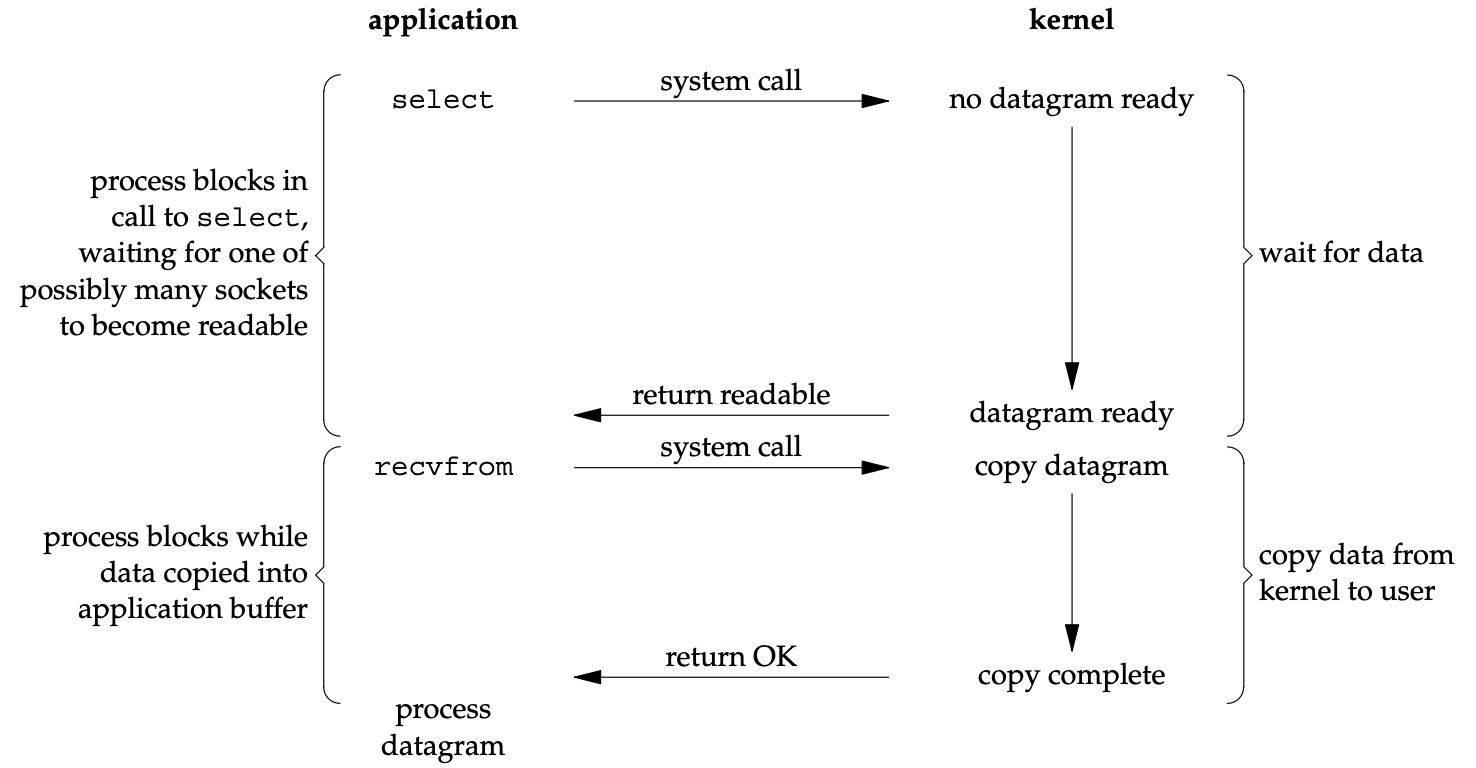
Another I/O model worth mentioning is I/O multiplexing, in which select, or poll system call is used to wait for one of a set of file descriptors to become ready to perform I/O.
In this model, the application blocks on one of these system calls, rather than on the actual I/O system calls, such as recvfrom shown in the figures above.
When select returns that the socket is readable, the application calls recvfrom to copy requested data to application buffer in user space.
 |
|---|
| I/O multiplexing model10 |
I/O Model in Go
Go uses a combination of non-blocking I/O and I/O multiplexing to handle I/O operations efficiently.
Due to the performance limitations of select and poll —as explained in this blog—Go avoids them in favor of more scalable alternatives: epoll on Linux, kqueue on Darwin, and IOCP on Windows.
Go introduces netpoll, a function that abstracts these alternatives, to provide a unified interface for I/O multiplexing across different OS.
How netpoll Works
Working with netpoll requires 4 steps: creating an epoll instance in kernel space, registering file descriptors with the epoll instance, epoll polls for I/O on file descriptors, and unregistering file descriptors from the epoll instance.
Let’s see how Go implements these steps.
Creating epoll Instance and Registering Goroutine
When a TCP listener accepts a connection, accept4 system call is invoked with SOCK_NONBLOCK flag to set the socket’s file descriptor of the socket to non-blocking mode.
Following this, several descriptors are created to integrate with Go runtime’s netpoll.
- An instance of
net.netFDis created to wrap the socket’s file descriptor. This struct provides a higher-level abstraction for performing network operations on the underlying kernel file descriptor. When an instance ofnet.netFDis initialized,epoll_createsystem call is invoked to create anepollinstance. Theepollinstance is initialized in thepoll_runtime_pollServerInitfunction, which is wrapped in async.Onceto ensure it runs only once. Because ofsync.Once, only a singleepollinstance exists within a Go process and is used throughout the lifetime of the process. - Inside
poll_runtime_pollOpen, Go runtime allocates aruntime.pollDescinstance, which contains scheduling metadata and references to the goroutines involved in I/O. The socket’s file descriptor is then registered with the interest list ofepollusingepoll_ctlsystem call withEPOLL_CTL_ADDoperation. Asepollmonitors file descriptors rather than goroutines,epoll_ctlalso associates the file descriptor with an instance ofruntime.pollDesc, allowing the Go scheduler to identify which goroutine should be resumed when I/O readiness is reported. - An instance of
poll.FDis created to manage read and write operations with polling support. It holds a reference to aruntime.pollDescindirectly viapoll.pollDesc, which is simply a wrapper.
⚠️ Go does have problem with a single
epollinstance as described in this open issue. There are discussions whether Go should use a single or multipleepollinstances, or even use another I/O multiplexing model likeio_uring.
Building on the success of this model for network I/O, Go also leverages epoll for file I/O.
Once a file is opened, syscall.SetNonblock function is called to enable non-blocking mode for the file descriptor.
Subsequently, poll.FD, poll.pollDesc and runtime.pollDesc instances are initialized to register the file descriptor with epoll’s interest list, allowing file I/O to be multiplexed as well.
The relationship between these descriptors is depicted in the figure below.
Meanwhile net.netFD, os.File, poll.FD, and poll.pollDesc are implemented in user Go code (specifically in the Go standard library), runtime.pollDesc resides within Go runtime itself.
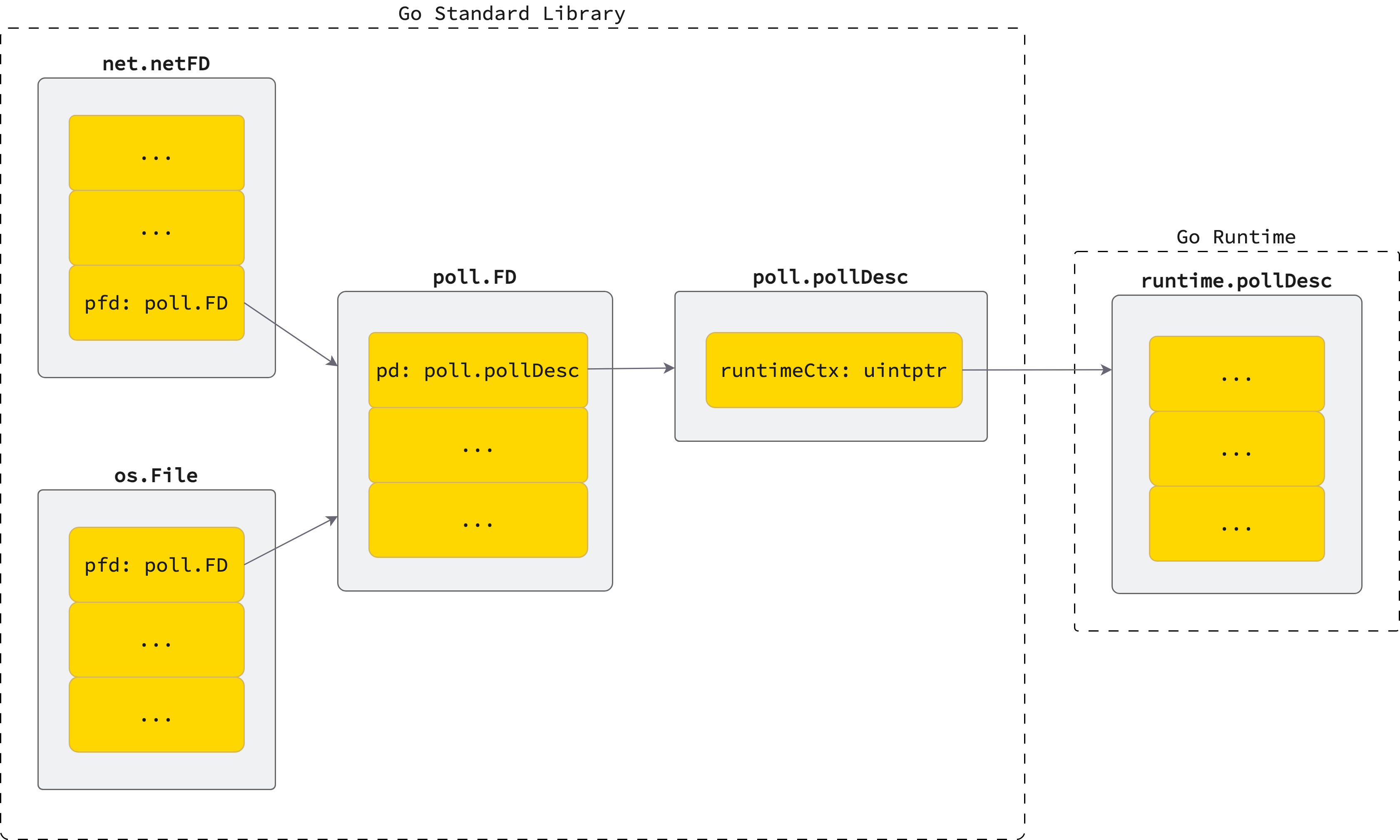 |
|---|
| Relationship of descriptors in Go |
Polling File Descriptors
When a goroutine reads from socket or file, it eventually invokes the Read method of poll.FD.
In this method, the goroutine makes read system call to get any available data from the file descriptor.
If the I/O data is not ready yet, i.e. EAGAIN error is returned, Go runtime invokes poll_runtime_pollWait method to park the goroutine.
The behavior is similar when a goroutine writes to a socket or file, with the main difference being that Read is replaced by Write, and the read system call is substituted with write.
Now that the goroutine is in waiting state, it is the responsibility of netpoll to present goroutine to the Go runtime when the goroutine’s file descriptor is ready for I/O so that it can be resumed.
In Go runtime, netpoll is nothing more than a function having the same name.
In netpoll function, epoll_wait system call is used to monitor up to 128 file descriptors in a specified amount of time.
This system call returns the runtime.pollDesc instances that were previously registered (as described in the previous section) for each file descriptor that becomes ready.
Finally, netpoll extracts the goroutine references from runtime.pollDesc and hands them off to the Go runtime.
But when is the netpoll function actually called?
It’s triggered when a thread looks for a runnable goroutine to execute, as outlined in schedule loop.
According to findRunnable function, netpoll is only consulted by the Go runtime if there are no goroutines available in either the local run queue of the current P or the global run queue.
This means even if its file descriptor is ready for I/O, the goroutine is not necessarily woken up immediately.
As mentioned earlier, netpoll can block for a specified amount of time, and this is determined by the delay parameter.
If delay is positive, it blocks for the specified number of nanoseconds.
If delay is negative, it blocks until an I/O event becomes ready.
Otherwise, when delay is zero, it returns immediately with any I/O events that are currently ready.
In the findRunnable function, delay is passed with 0, which means that if one goroutine is waiting for I/O, another goroutine can be scheduled to run on the same kernel thread.
Unregistering File Descriptors
As mentioned above, epoll instance monitors up to 128 file descriptors.
Therefore, it’s important to unregister file descriptors when they are no longer needed otherwise some goroutines may be starved.
When file or network connection is no longer in used, we should close it by calling its Close method.
Under the hood, the destroy method of poll.FD is called.
This method eventually invokes the function poll_runtime_pollClose in Go runtime to make epoll_ctl with EPOLL_CTL_DEL operation.
This unregisters the file descriptor from the epoll’s interest list.
Putting It All Together
The figure below illustrates the entire process of how netpoll works in Go runtime with file I/O.
The process for network I/O is similar, but with the addition of a TCP listener that accepts connection and connection is closed.
For simplicity purpose, other components in such as sysmon and other idle processors P are omitted.
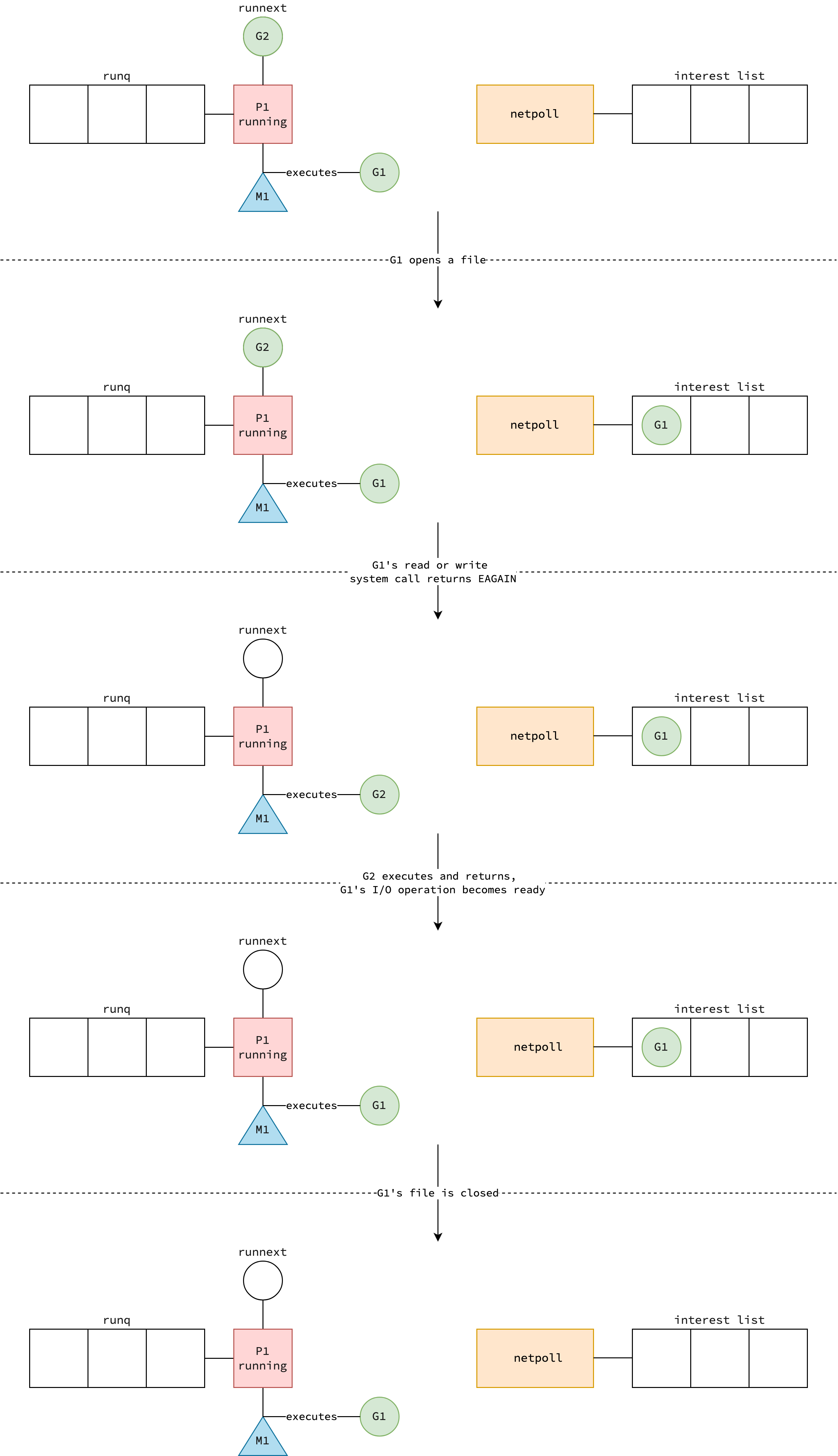 |
|---|
| How netpoll works in GMP model |
Garbage Collector
You may know that Go includes a garbage collector (GC) to automatically reclaim memory from unused objects. However, as mentioned in the Program Bootstrap section, when the program starts, there are no threads initially available to run the GC. So where does the GC actually run?
Before we answer that question, let’s take a quick look at how garbage collection works. Go uses a tracing garbage collector, which identifies live and dead objects by traversing the allocated object graph starting from a set of root references. Objects that are reachable from the roots are considered live; those that are not are considered dead and eligible for reclamation.
Go’s GC implements a tri-color marking algorithm with support for weak references. This design allows the garbage collector to run concurrently with the program, significantly reducing stop-the-world (STW) pauses and improving overall performance.
A Go garbage collection cycle can be divided into 4 stages:
- First STW: The process is paused so that all processors
Pcan enter the safe point. - Marking phase: GC goroutines takes processor
Pshortly to mark reachable objects. - Second STW: The process is paused again to allow the GC to finalize the marking phase.
- Sweeping phase: Unpause the process and reclaim memory for unreachable objects in background.
Note that in step 2, garbage collection worker goroutine runs concurrently with regular goroutines on the same processor P.
The findRunnable function (mentioned in Finding a Runnable Goroutine section) not only looks for regular goroutines but also for GC goroutines (step 1 and 2).
Common Functions
Getting Goroutine: getg
In Go runtime, there is a common function that is used to retrieve the running goroutine in current kernel thread: getg().
Taking a glance at the source code, you can see no implementation for this function.
That’s because upon compiling, the compiler rewrites calls to this function into instructions that fetch the goroutine from thread-local storage (TLS) or from registers.
But when is the current goroutine stored in thread-local storage so it can be retrieved later?
This happens during a goroutine context switch in the gogo function, which is called by execute.
It also takes place when a signal handler is invoked, in the sigtrampgo function.
Goroutine Parking: gopark
This is a commonly used procedure in Go runtime for transitioning the current goroutine into a waiting state and scheduling another goroutine to run. The snippet below highlights some of its key aspects.
func gopark(unlockf func(*g, unsafe.Pointer) bool, ...) {
...
mp.waitunlockf = unlockf
...
releasem(mp)
...
mcall(park_m)
}
Inside releasem function, the goroutine’s stackguard0 is set to stackPreempt to trigger an eventual cooperative preemption.
The control is then transferred to the g0 system goroutine, which belongs to the same thread currently running the goroutine, to invoke the park_m function.
Inside park_m, the goroutine state is set to waiting and the association between the goroutine and thread M is dropped.
Additionally, gopark receives an unlockf callback function, which is executed in park_m.
If unlockf returns false, the parked goroutine is immediately made runnable again and rescheduled on the same thread M using execute.
Otherwise, M enters the schedule loop to pick a goroutine and execute it.
Start Thread: startm
This function is responsible for scheduling a thread M to run a given processor P.
The diagram below illustrates the flow of this function, in which M1 thread is the parent of M2 thread.
flowchart LR
subgraph M2
direction LR
mstart["mstart()"] ==> mstart0["mstart0()"]
mstart0 ==> mstart1["mstart1()"]
mstart1 ==> schedule["schedule()"]
end
subgraph M1
direction LR
start((Start)) ==> check_p{P == nil?}
check_p ==> |Yes|check_idle_p{Is there any idle P?}
check_idle_p ==> |No|_end(((End)))
check_idle_p ==> |Yes|assign_p[P = idle P]
check_p ==> |No|check_idle_m{Is there any idle M?}
assign_p ==> check_idle_m
check_idle_m ==> |Yes|wakeup_m[Wake up M]
wakeup_m ==> _end
check_idle_m ==> |No|newm["newm()"]
newm ==> newm1["newm1()"]
newm1 ==> newosproc["newosproc()"]
newosproc ==> clone["clone() with entry point mstart, results in M2 thread"]
clone ==> _end
end
|
The startm function
|
If P is nil, it attempts to retrieve an idle processor from the global idle list.
If no idle processor is available, the function simply returns—indicating that the maximum number of active processors is already in use and no additional thread M can be created or reactivated.
If an idle processor is found (or P was already provided), the function either creates a new thread M1 (if none is idle) or wakes up an existing idle one to run P.
Once awakened, the existing thread M continues in the schedule loop.
If a new thread is created, it’s done via the clone system call, with mstart as the entry point.
The mstart function then transitions into the schedule loop, where it looks for a runnable goroutine to execute.
Stop Thread: stopm
This function adds thread M into the idle list and put it into sleep.
stopm doesn’t return until M is woken up by another thread, typically when a new goroutine is created, as mentioned in Waking Up Processor section.
This is achieved by futex system call, making M not eating CPU cycles while waiting.
Processor Handoff: handoffp
handoffp is responsible for transferring the ownership of a processor P from a thread Ms that is blocking in a system call to another thread M1.
P will be associated with M1 to make progress by calling startm under certain conditions: if the global run queue is not empty, if its local run queue is not empty, if there is tracing work or garbage collection work to do, or if no thread is currently handling netpoll.
If none of these conditions is met, P is returned to the processor idle list.
Go Runtime APIs
Go runtime provides several APIs to interact with the scheduler and goroutines. It also allows Go programmers to tune the scheduler and other components like garbage collector for their application specific needs.
GOMAXPROCS
This function sets the number of processors P in Go runtime, thus controlling the level of parallelism in a Go program.
The default value of GOMAXPROCS is the value of runtime.NumCPU function, which queries the operating system CPU allocation for the Go process.
GOMAXPROCS’s default value can be problematic, particularly in containerized environments, as described in this awesome post.
There is an ongoing proposal to make GOMAXPROCS respect CPU cgroup quota limits, improving its behavior in such environments.
In future versions of Go, GOMAXPROCS may become obsolete, as noted in the official documentation: “This call will go away when the scheduler improves.”
Some I/O bound programs may benefit from a higher number of processors P than the default.
For example, Dgraph database hardcodes GOMAXPROCS to 128 to allow more I/O operations to be scheduled.
Goexit
This function gracefully terminates the current goroutine.
All deferred calls run before terminating the goroutine.
The program continues execution of other goroutines.
If all other goroutines exit, the program crashes.
Goexit should be used testing rather than real-world application, where you want to abort the test case early (for example, if preconditions aren’t met), but you still want deferred cleanup to run.
Conclusion
The Go scheduler is a powerful and efficient system that enables lightweight concurrency through goroutines. In this blog, we explored its evolution—from the primitive model to the GMP architecture—and key components like goroutine creation, preemption, syscall handling, and netpoll integration.
I hope you find this knowledge useful for writing more efficient and reliable Go programs.
If you have any concerns, feel free to leave a comment.
If you really enjoyed my content, please consider
 ! 😄
! 😄
References
- kelche.co. Go Scheduling.
- unskilled.blog. Preemption in Go.
- Ian Lance Taylor. What is system stack?
- [6], [7] Michael Kerrisk. The Linux Programming Interface.
- [8], [9], [10] W. Richard Stevens. Unix Network Programming.
- zhuanlan.zhihu.com. Golang program startup process analysis.
- Madhav Jivrajani. GopherCon 2021: Queues, Fairness, and The Go Scheduler.
-
[1], [2], [3] Abraham Silberschatz, Peter B. Galvin, Greg Gagne. Operating System Concepts.